
我要认证
2026-06-21
按住下方图标,点击小程序
免费领取AI学习资料、精选提示词

做AI应用的朋友多少都踩过这样的坑,你把公司里的文档、Wiki、代码仓库一股脑塞进大模型。
结果发现AI答非所问,token费用高得吓人,更糟的是不同文档里重复的内容被反复喂给模型,账单直接翻倍。
这就是当下大多数RAG系统的真实困境,文档被粗暴切成固定大小的碎片,语义断在句子中间,重复内容像野草一样疯长。
今天给大家介绍一个性能非常强的企业级RAG开源Blockify来解决这个大难题。
开源地址:https://github.com/iternal-technologies-partners/blockify-agentic-data-optimization
简单来说,Blockify本质上是一个面向企业RAG和智能搜索的数据优化框架,可以用结构化的知识单元替代粗暴的文本切片,让AI真正读懂你的业务文档。
那Blockify到底是怎么进行高性能优化的呢,下面给大家好好唠唠。
传统切片工具不管三七二十一,按字符数硬切,经常把一句话拦腰斩断,把一个完整的概念拆得七零八落。
Blockify的摄入模块会真正读懂内容的意思,把每段文字提炼成一个IdeaBlock,也就是知识块。
每个知识块都自带问题、答案、标签、实体和关键词,像一个自给自足的小宇宙。
这好处也显而易见,模型检索的时候拿到的不再是半截话,而是一个完整的语义单元,理解起来自然顺畅得多。好比你看书的时候,拿到的是一页完整的纸,而不是被撕碎的纸条拼图。
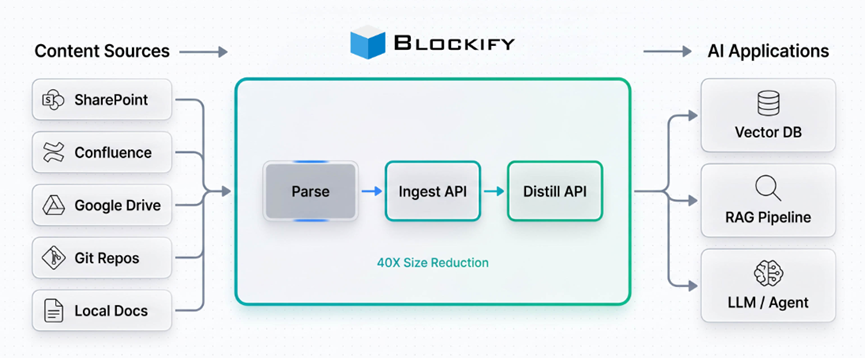
企业里重复内容多到让人崩溃,同一套操作手册可能在各个部门各存一份,同一段产品介绍可能在几十个文档里反复出现。这些重复不仅浪费存储,更会让向量空间挤满近似副本,检索精度直线下降。
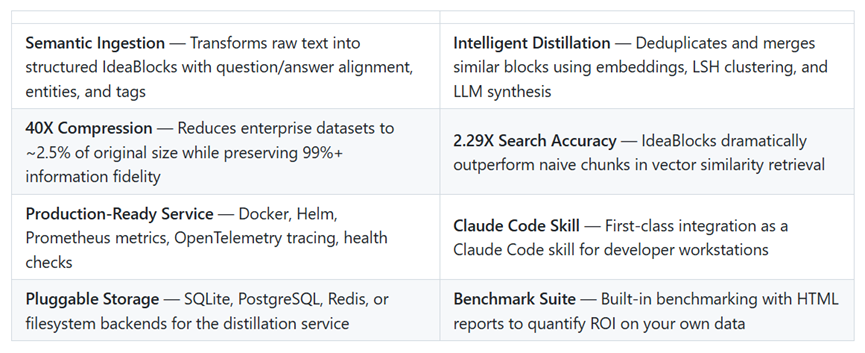
Blockify的蒸馏模块用嵌入向量加局部敏感哈希做聚类,再用大模型把相似的知识块合并去重。
根据官方数据显示,Blockify整体的精华压缩比高达40倍,信息保真度还能保持在99%以上。
检索精度翻倍,幻觉大幅减少。这是最直观的体感提升。官方benchmark显示向量检索精度提升2.29倍,平均距离从0.36降到0.16。
翻译成人话就是,模型找到的答案更准了,张冠李戴的情况少多了。
原因也不复杂,去重之后向量空间里每个方向上都是真正不同的知识点,topK检索自然能捞出更相关的内容,而不是返回十份几乎一样的产品介绍。
Token消耗直降3倍。这点对烧钱做AI应用的团队特别友好。
传统切片每个chunk平均300多个token,Blockify的知识块只要98个左右,效率提升3倍多。一年跑十亿次查询的话,光token费用就能省下不少钱。
登录/注册后继续阅读
立即登录/注册 >上一篇: 学完AI,然后呢?很多人卡在这里






























