
我要认证
2026-06-23
按住下方图标,点击小程序
免费领取AI学习资料、精选提示词

平时我们拿到一份长文档,想从中提取有用信息,传统做法是什么?
自己硬读,或者写一堆正则规则去匹配关键词。前者太慢,后者太脆弱,换个格式的文档就全废了。
后来有了大语言模型,情况好了一些,但你要想从一段文本里把实体关系、时间线、空间位置这些复杂结构都提取出来,还是得自己写很多提示词,调很多参数,搞很多后处理逻辑,这个过程相当痛苦。
今天就为大家介绍一个好用的开源Hyper-Extract,来解决这个难题。

开源地址:https://github.com/yifanfeng97/Hyper-Extract
其实你压根不用费劲去设计什么提示词模板,也不需要纠结该用什么参数。
只要部署好项目敲一行命令he parse,把文档路径指给Hyper-Extract,剩下的事情全交给AI去完成就可以了。
咱们在唠唠Hyper-Extract的主要特色功能,第一点是对文档的理解深度和广度很强。
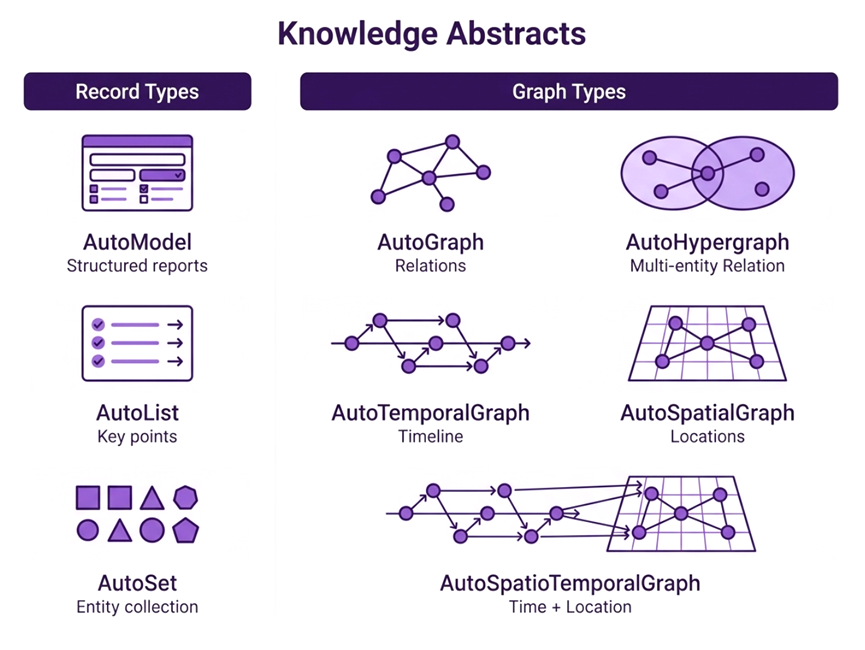
能处理成图谱、超图,还能把时间和空间信息揉进去。这意味着你拿一份历史资料,能按时间线给你捋清楚;
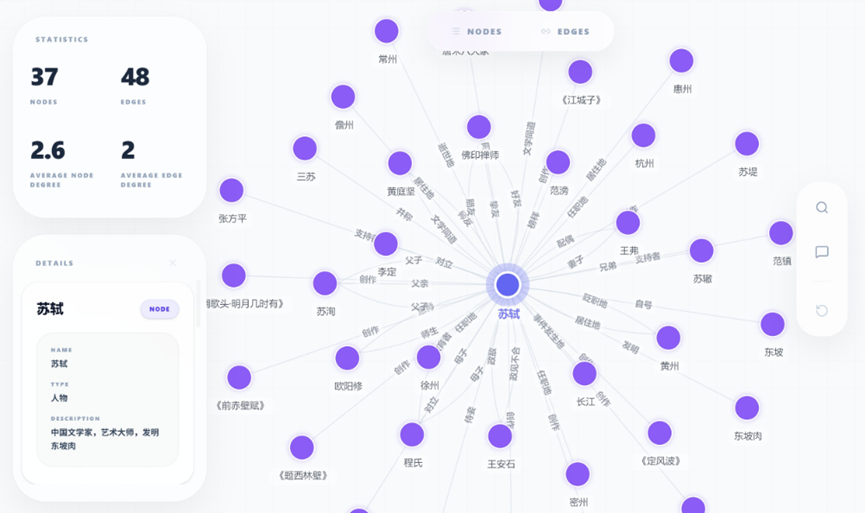
拿一份地理报告,能在地理维度上给你呈现空间关系,不是简单列几个关键词就完事了。
第二点是模板系统很贴心。项目里预置了80多种不同行业的解析方案,涵盖金融、法律、医疗这些专业领域。
你不需要自己去琢磨怎么配置,就像点菜一样选一个合用的模板就能直接开工。
比如处理医疗文献就选医疗相关的模板,法律条文就选法律相关的模板,省下了大量摸索的时间。
第三个是支持增量更新,这功能简直救命。之前用别的工具,每次有新资料进来,都得把所有数据从头再跑一遍,时间全浪费在等待上了。
Hyper-Extract不一样,你随时可以把新文件丢进去,它会自动在原来整理好的基础上扩充新内容,不用反复折腾。知识库随着文档增多越变越完整,完全不用你操什么心。
再说说这个工具对笔记爱好者有多友好。支持一键导出成 Obsidian 能直接用的 Markdown 格式,里面那些双链都是自动生成好的。
你本来就在 Obsidian 里搭建知识体系的话,这个功能简直是完美衔接。解析完的图谱直接变成你的个人知识网络,整个过程行云流水。
登录/注册后继续阅读
立即登录/注册 >





























