
我要认证
2026-06-24
按住下方图标,点击小程序
免费领取AI学习资料、精选提示词

百度刚刚开源了一个重磅模型Unlimited OCR。
咱们平时用OCR,处理几页还行,一旦遇到几十页的长文档,速度就开始肉眼可见地变慢,最后甚至直接卡死。
而Unlimited OCR可以一口气处理40页PDF不卡顿,而且处理效率超快!

开源地址:https://huggingface.co/baidu/Unlimited-OCR
https://github.com/baidu/Unlimited-OCR
Unlimited OCR创新架构
Unlimited OCR跟我印象里的OCR完全不是一个画风。平时我们用那些识别工具,前几页还行,到后面明显感觉速度慢下来,甚至有时候直接卡死崩溃。不是网络问题,是模型自己撑不住了。
那为什么会慢呢。其实很简单,现在大多数端到端OCR模型都拿大语言模型当解码器,用语言先验知识来提高识别准确率。这个思路本身没问题,但有个特别要命的副作用。
每生成一个新token,模型都要把之前生成的所有内容存下来当参考,这个缓存叫KV cache。输出越长,缓存越大,跟滚雪球一样。内存被吃光不说,生成速度也肉眼可见地往下掉。
Unlimited OCR就聪明很多,直接把核心的注意力机制给修改了,改成参考滑动窗口注意力简称R-SWA。
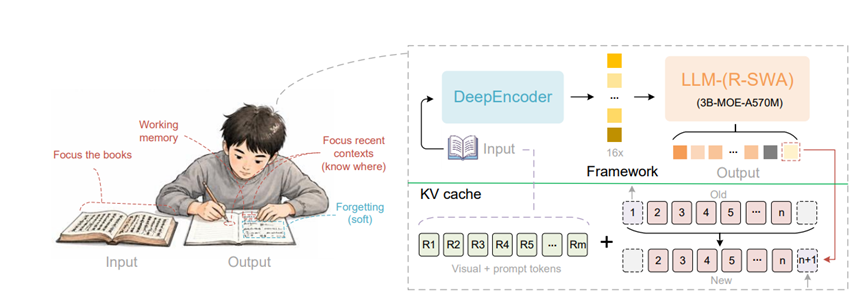
名字听着有点唬人,但其实特别好理解。每个新生成的token只看两部分内容,一部分是图片里所有的视觉特征和用户输入的提示,这部分永远是全量的,因为那是识别依据,不能丢。
另一部分是它前面刚生成的128个token,也就一两句话的长度。再往前的内容,模型直接就忘了。
R-SWA就是把这种机制搬到了模型里。一个固定大小的滑动窗口,只保留最近128个token的缓存,新的进来,老的出去,就这样循环滚动。
视觉参考token不在这个滑动窗口里,它们是单独保留的,始终完整。
架构方面,Unlimited OCR是在DeepSeek OCR基础上改造的,但保留了DeepEncoder编码器。
这个编码器压缩率相当高,采用级联的窗口注意力和全局注意力ViT,能做到16倍的token压缩,也就是原来16个视觉token被压成1个。
解码器部分用了混合专家架构,总参数量3B,但每次推理只激活500M,所以实际跑起来很轻量。
40页PDF一次性解析完
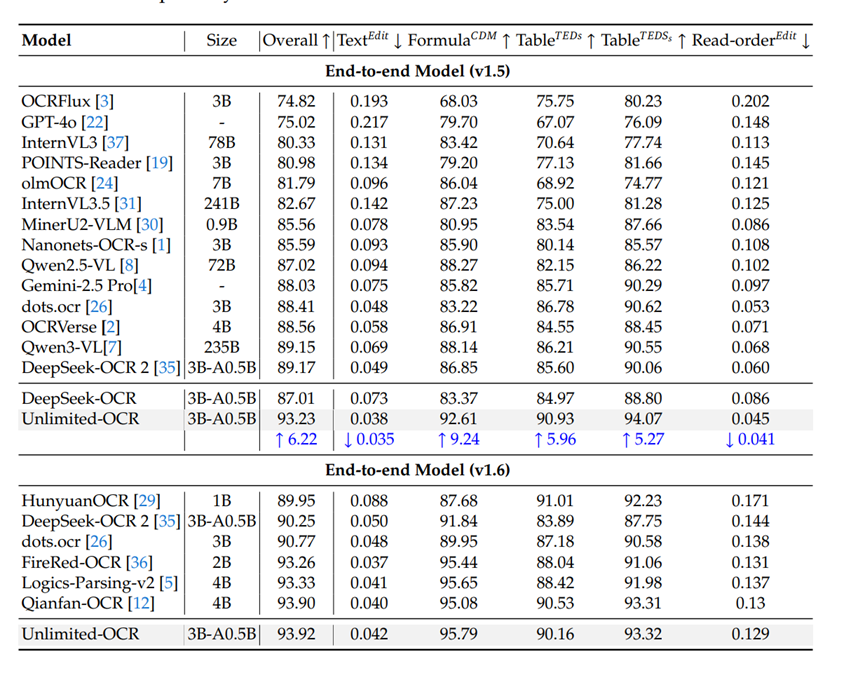
为了测试Unlimited OCR的性能,开发团队在多个主流基准测试进行了综合评估,结果都非常出色。
在权威的OmniDocBench v1.5测试中,UnlimitedOCR拿到了93.23分,比老前辈DeepSeekOCR高出6.22分。
文本编辑距离只有0.038,几乎不需要怎么改就能直接用。在最新的v1.6版本测试里,它拿到了93.92的惊人分数,直接刷新了榜单,把GPT-4o、Qwen3-VL之类的大家伙都甩在了身后
登录/注册后继续阅读
立即登录/注册 >





























