
我要认证
2026-06-26
按住下方图标,点击小程序
免费领取AI学习资料、精选提示词

刚刚大模型开源圈来了个大黑马Ornith-1.0,是一个主打AI智能体编码的大模型。
一共有9B、31B、35B和397B四种参数,适配了手机、个人PC、企业、数据中心不同类型用户。
根据官方公布的测试数据显示,Ornith-1.0的397B模型在多个主流测试中,性能小幅度超越Claude的顶配模型Opus 4.7,大幅度超过了DeepSeek V4和Minimax-M3。
开源地址:https://huggingface.co/collections/deepreinforce-ai/ornith-10
测试数据
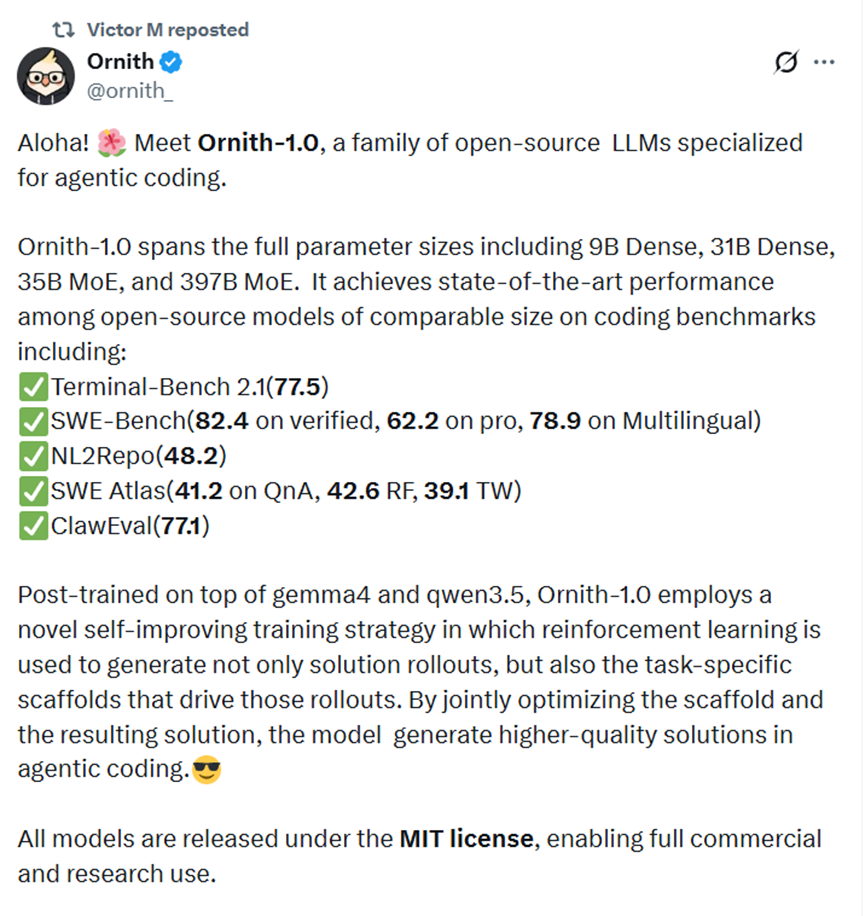
咱们先来看看实测成绩单。Ornith-1.0-397B这个旗舰款,在Terminal-Bench 2.1上拿了77.5分,在SWE-Bench Verified上拿了82.4分,直接把Claude Opus 4.7给超了。
也明显领先同体量的MiniMax M3和DeepSeek-V4-Pro。
其实这个成绩的含金量很高的。长久以来,开源代码模型普遍存在短板,在专业工程级代码任务中,性能大多逊色于Claude这类顶级闭源商用模型。
而Ornith-1.0 397B版本,是少有的在核心代码测评维度,实现开源反超主流闭源顶配的模型,大幅拉高了开源代码模型的性能天花板。
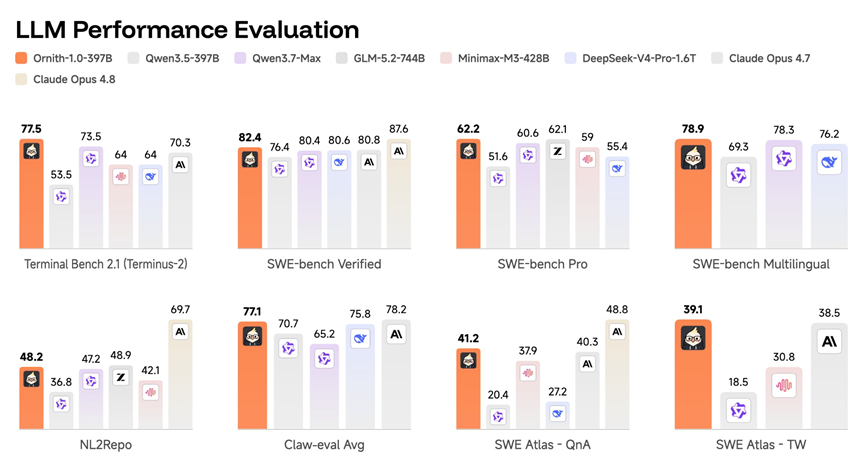
再看实用性拉满的35B混合专家版本,非常适配中小企业和个人开发者的使用场景。它的参数规模不算庞大,
但专项优化做得极其到位,多项核心代码测评数据,全面领先同参数梯队的通义千问3.5、通义千问3.6以及Gemma4-31B模型。
在Terminal-Bench 2.1终端任务场景中,35B版本得分超越了参数规模远超自己的通义千问3.5-397B超大模型,足以证明针对性代码优化,远比单纯堆叠参数更有效。
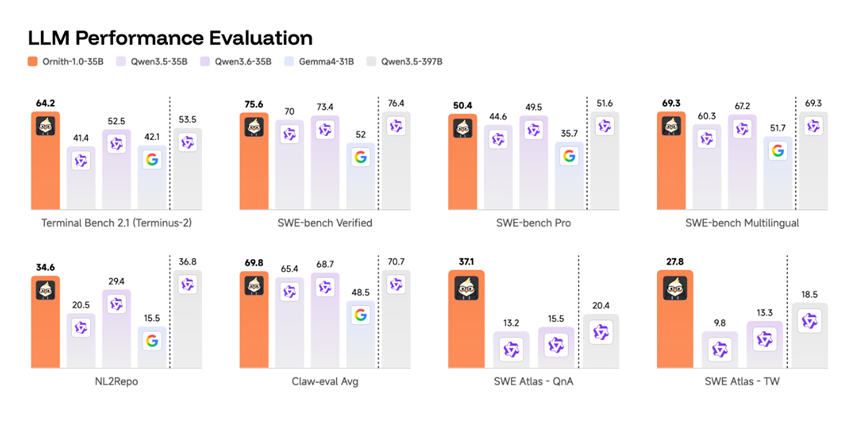
在说说门槛低、亲民的9B稠密轻量化版本,也是普通开发者本地部署、端侧使用的优选版本。
它对硬件配置要求极低,普通设备就能流畅运行,且性能表现十分均衡。
实测数据显示,这款小体量模型的综合代码能力,能够持平甚至小幅超越Gemma4-31B这类数十B参数的大尺寸模型。
轻量化部署的性价比优势特别突出,这对个人开发者和小型团队很友好的。
Ornith-1.0核心创新
传统做法里,你要让模型通过强化学习来学会写代码解题,通常需要人提前设计好一套测试框架,学术上叫 harness,你可以理解为考试用的阅卷系统。模型只管答题,框架负责判分。
而 Ornith 做了一件挺疯狂的创新,让AI模型自己来设计这套阅卷系统。
每一轮强化学习分两步走。第一步,模型看看手头的任务和之前用过的框架,然后提出一个改进版的新框架。
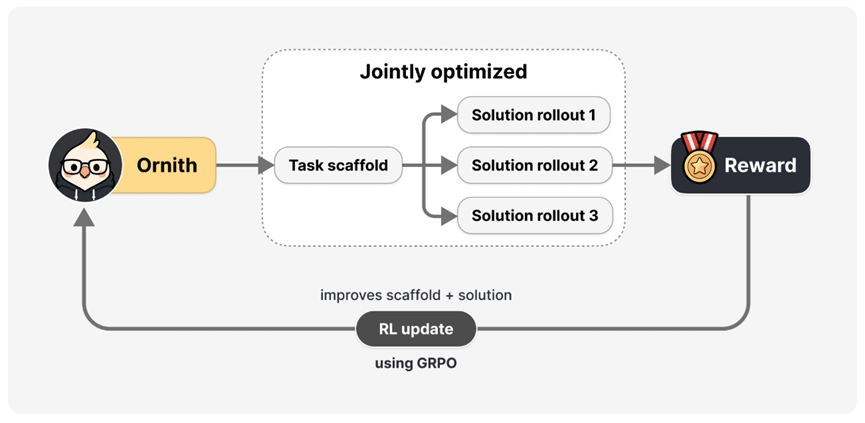
第二步,模型基于这个新框架去生成解题过程。最后跑出来的结果好不好,奖励信号会同时回传给这两个阶段。
这意味着模型不光在学习怎么把题做对,同时也在学习怎么设计一个更好的判题系统来引导自己找到更优的解法。
你可以把这种操作想象成一个学生,不光在疯狂刷题,还在不断优化自己的学习方法论。
训练一轮一轮跑下去,框架就会不断变异和筛选,朝着能产生更高分的方向进化。每个任务类型的最优策略就这么自动冒出来了,完全不需要人去手工设计。
不过话说回来让模型自己写框架,有一个很关键的问题,模型会不会偷懒作弊呢?
三层防线防止AI偷懒
答案确实是会。自生成的框架可能学到一些取巧的路子,比如偷偷读测试文件然后把答案硬编码进去,或者直接把环境里已经存在的标准答案抄过来。
登录/注册后继续阅读
立即登录/注册 >





























