
我要认证
2026-06-28
按住下方图标,点击小程序
免费领取AI学习资料、精选提示词

平时咱们用大模型,最心烦的就是遇上一卡一卡的对话,或者问个复杂点的问题要干等半天。
其实大模型背后的工作模式挺笨,每蹦一个词就要把整个脑子重新过一遍。
业内想了不少招,比如推测解码,派个小号模型先瞎猜几个词,大模型再核对,但效果都不理想。
DeepSeek联手北大刚开源了一个加速推理框架DSpark,专治这个老毛病。

开源地址:https://github.com/deepseek-ai/DeepSpec
老方案差在哪
咱们先聊聊以前那些加速方案到底差在哪。就拿自回归草稿来说吧,就像老学究写字,非得写完一个字再琢磨下一个。好处是上下文连得上,但速度天生就有个天花板。
你想多猜几个词,耗时就成倍往上涨,工业部署时只能逼着少猜点。还有一种并行草稿,有点像发扑克牌,一把甩出去十几个候选词,速度确实快,但毛病在于词和词之间没有任何联系。
比如上文是今天天气真,可能随手甩出个吃汉堡,后半段直接精神分裂。这种没头没脑的预测越往后错得越离谱,大模型一看全给毙了,前面花的心血全打水漂。
除了模型自己瞎猜浪费算力,线上的调度系统也挺让人头疼的。以前的验证逻辑非常死板,不管你是写严谨的代码还是在跟AI扯淡闲聊,系统都给安排一模一样的核对长度。
这就好比你开个饭店,不管客人点一盘花生米还是满汉全席,后厨都按最大规格开火。低峰期时GPU闲着也是闲着,浪费点就算了。
一到晚上高峰期大伙儿全挤进来,那些没用的校验请求还在占着大厨的锅,直接导致后面排队的人全卡死,整个服务器的吞吐量直接跳水。这就是大家常说的AI大模型高并发崩盘,一遇到人多就歇菜。
DSpark破局妙招
DSpark的破局招数挺绝,第一板斧就砍在了草稿模型的结构上,搞了个半自回归生成。
这名字听着玄乎,其实可以把它当成一个流水线作业。前面那个发扑克牌的骨干网络还在,一次性把十几个候选词全抛出来,保证速度够快。
但紧接着加了个轻量级的串行修正头,相当于派了个质检员飞速过一遍,看看词和词连起来通不通顺。
如果前面发了个吃,质检员赶紧把后面的汉堡压下去,把饭的优先级抬上来。
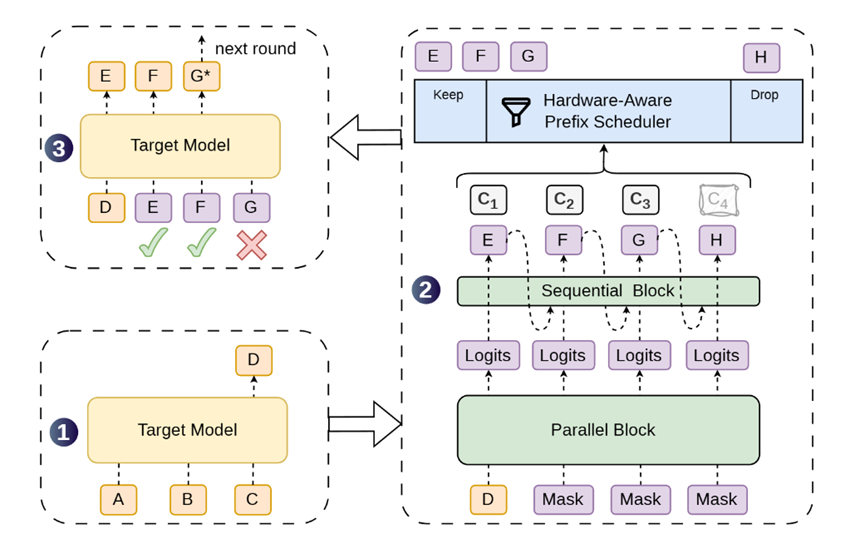
这个过程快得离谱,仅仅带来百分之一不到的延迟上浮,但效果立竿见影。原来后半段被疯狂拒绝的词,现在存活率直线上升。
测试数据显示,就两层网络深度的DSpark,猜词准头直接碾压五层深度的老方案。不管模型是做数学题还是陪人聊天,平均一次能被采纳的词数都拉长了一大截。
光猜得准还不够,DSpark的第二板斧对准了系统调度,这可是治高并发崩盘的特效药。既然有些请求明明猜得很没谱,干嘛还要让大模型费劲去一个个核对。
团队就弄了个置信度预测头,专门给每个候选词打个信任分。
但这分一开始打得不太准,模型经常盲目自信。于是又加了个校准算法,把误差硬生生压到百分之一以内。有了这分数,硬件感知调度器就能干活了。
这调度器简直是个精打细算的管家婆。当服务器没什么人用时,会把核对长度拉长,哪怕多核对几个不太确定的词也无所谓,反正闲着也是闲着,争取让每个用户拿到的回复多一点。
一旦网上涌进来一堆人,GPU快撑不住了,它马上变脸,咔咔把那些低分的候选词全砍掉,保住主干流程不崩。
登录/注册后继续阅读
立即登录/注册 >





























