
我要认证
2026-04-05
那个拍出《怪奇物语》、《纸牌屋》、《暗夜情报员》的流媒体巨头Netflix,最近干了件让整个后期圈炸锅的事。
他们开源了一个叫VOID的视频修复模型,不仅能删除视频中的物体,还能理解物理因果关系,让删除后的画面看起来像那个东西从未存在过一样自然。
例如,你想删掉视频里一个人,传统工具只能把人糊掉,背景还得手动补。
而VOID不仅能把人干净地移除,连他投射的影子、他手中即将掉落的杯子,都会按照物理规律自然地消失或坠落。
这种效果,放在以前只有烧钱请顶级特效团队才能做到。这也是Netflix开源这个模型的核心原因之一。
他们自己的影视制作团队就长期面临这个痛点,现在干脆把解决方案做成了通用工具,直接送给所有人用。
开源地址:https://huggingface.co/netflix/void-model
https://github.com/netflix/void-model
做过视频编辑的人都知道,从视频里干净利落地删掉一个物体,这件事说起来简单,做起来极其折磨人。
早期的做法就是用类似"橡皮擦"的工具把目标区域遮住,再用周围像素填充。静止画面勉强能看,一旦物体在运动,帧间抖动和画质劣化根本藏不住。
有人用AE做精细化处理,效果好了不少,但技术门槛高、耗时极长,普通人根本玩不转。
再后来扩散模型兴起,视频修复质量确实上了一个台阶,但始终有一个核心问题没有解决,物理交互。
一个人靠在墙上,你把人删了,墙上应该留什么?一个人正要端起桌上的杯子,人消失后杯子是停在半空还是倒下?
这些对人类不难的物理判断,对AI模型来说却极其困难,因为它需要理解三维空间中的因果关系,而不只是在像素层面做填充。而VOID要解决的就是这些难题。
VOID的核心创新是一个叫四值遮罩的设计。听起来很学术,但思路其实非常直觉:它把画面中的每一个像素标记为四种状态之一删除目标、重叠边界、受影响区域、保持原样的背景。
这四个值编码了三种语义层面的信息。0代表你要删掉的主体物体。63代表主体物体与周围环境重叠的区域,模型需要特别注意这里的过渡处理。
127是最关键的部分,它标记的是因为主体消失而会受到连锁影响的区域,被遮挡的背景、会掉落的物品、投射的阴影、产生的倒影,这些都属于"物理交互"的范畴。255则是完全不需要动的背景区域。
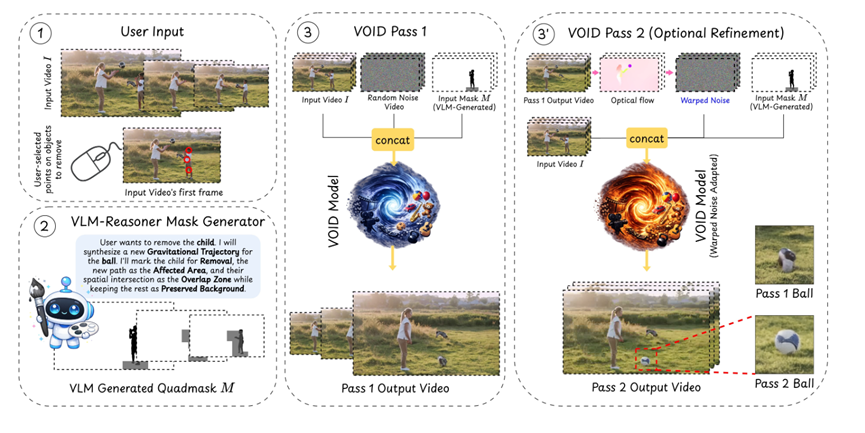
有了这张指令地图,模型在重新生成画面时,就不只是在盲目填充像素,而是有明确的方向,哪里该抹掉,哪里该修复,哪里需要重新想象物理后果。
那这个四值遮罩怎么生成?手动标注显然不现实。VOID用的是一套两步走的自动化管线,巧妙地把视觉感知和语言推理结合在了一起。
第一步,用Meta的SAM2做实例分割。SAM2是目前最成熟的视频分割模型之一,能高精度地把画面中的每个物体单独圈出来,这是整个流程的基础。
第二步才是真正精彩的部分,调用谷歌的Gemini大语言模型来做物理推理。系统会把SAM2识别出的物体关系用文字描述发给Gemini,让它判断哪些区域会因为目标物体的消失而受到影响。
比如画面中有一个人站在纸箱子旁边,Gemini需要推理出:人消失了,纸箱子不受影响,但人身上的影子需要处理掉,人手里拿着的东西会掉下来。这种视觉分割加语言理解的组合拳,效果出奇地好,而且生成成本并不高。

模型架构方面,VOID基于阿里开源的CogVideoX-Fun-V1.5-5b-InP进行微调,这是一个50亿参数的3D Transformer模型,本身就为视频修复任务做了专门优化。Netflix在这个基础上进一步注入了物理交互感知的能力。
模型接收三个输入,原始视频、四值遮罩、以及一段文字描述。文字描述告诉模型删除之后场景应该呈现什么样子,比如"草地上的背景"之类,给模型一个生成的大方向。
推理默认分辨率为384×672,最大支持197帧。调度器用的是DDIM,精度方面采用BF16搭配FP8量化来节省显存。
50亿参数跑在FP8下,显存开销大幅降低,最终把最低显存需求压到了40GB,一张A100就能跑。
处理流程分两个阶段。Pass 1是基础修复,负责把目标物体移除并重新生成画面,这是必须执行的阶段,对大多数短视频场景已经足够。
登录/注册后继续阅读
立即登录/注册 >






























