
我要认证
2026-04-05
最近谷歌DeepMind放出一篇重磅论文,讲的是怎么让AI大模型自己去进化出全新的多智能体学习算法。
听起来有点抽象对吧,其实就是以前那些下棋打牌特别厉害的AI算法,都是咱们人类工程师一点点抠细节调出来的,过程特别像是在大海捞针。
现在他们把这个活直接丢给AI了,而且AI还真干成了,弄出来的新算法在很多标准测试里把人类专家精心设计的方案按在地上摩擦。

论文:https://arxiv.org/pdf/2602.16928
要理解这事,咱们得先聊聊背景。平时大家看AI下扑克或者玩实时战略游戏,背后其实都有一套博弈论数学框架在撑着。
里面有个很重要的概念叫可利用度,你可以把它理解成策略里的破绽值。这个数值越低,说明你的策略越完美,别人越占不到你便宜。
而为了让这个破绽值赶紧降下来,人类前辈们发明了两大算法家族,一个叫CFR,另一个叫PSRO。
这俩算法就像是两套不同的练功心法。CFR比较老实,就是不断地算自己当初要是选了别的动作会不会更好,然后把这种后悔的感觉一点点攒起来,最后算出一个平均策略。
PSRO呢则像是在带徒弟,它先找出一堆不同的打法组成一个门派,然后看看怎么组合这些打法去对抗别人,接着再针对性地培养出更强的徒弟加入门派。
问题就出在练功心法的细节上。比如怎么把以前的经验折旧,怎么把不同打法混合起来,这些细节里有无数种组合方式。
人类工程师只能靠直觉去猜去试,很多时候就默认用一些最简单的线性计算或者固定的折扣比例。这种做法在海量的可能性面前其实挺无力的,很容易就错过那些看起来不按套路出牌但其实特别高效的招式。

为了打破这个僵局,DeepMind掏出了他们的秘密武器Alpha Evolve。这套系统特别有意思,把大语言模型当成了会写代码的基因编辑器。
一开始它手里拿着的是咱们人类写好的标准算法代码,然后大模型就开始发挥它的想象力,去修改里面的逻辑。这不是像以前那样随便改个参数或者调个学习率,它是直接重写算法的核心运行逻辑。
这个过程其实特别像养蛊。每次修改完代码,系统就会把新算法扔到几个小的棋盘游戏里去跑,看看破绽值降得快不快。
跑得好的就留下来,跑得不好的就淘汰。然后大模型再拿这些活下来的代码继续改。就这么循环往复,改了不知道多少代之后,奇迹就出现了。
AI首先在CFR这个家族里进化出了一个叫VAD-CFR的新变种。这个新算法的做法完全打破了人类的老观念。咱们人类以前总喜欢固定一个节奏去遗忘旧经验,但VAD-CFR不是这样,它会自己盯紧局势的波动情况。
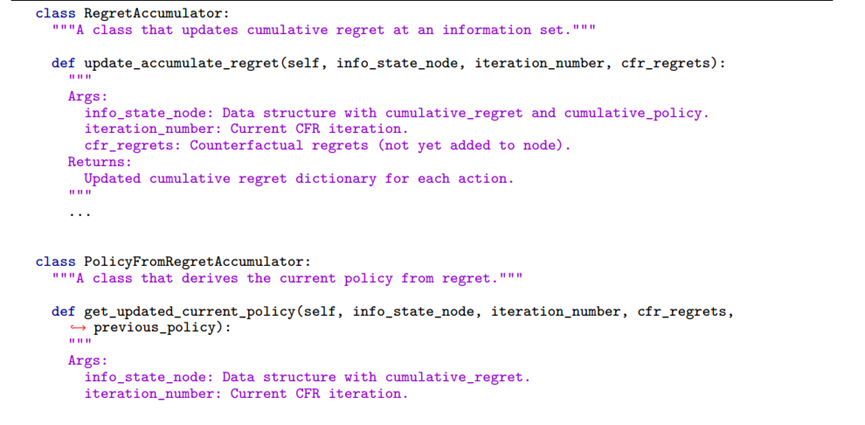
如果发现策略变来变去特别混乱,它就干脆利落把旧经验忘得快一点,免得被噪声带偏。等局势稳下来了,它再慢慢吸收以前的经验。
而且它对那些刚刚发现的好动作特别敏感,会立刻给它们加上buff,不等待慢慢累积。最绝的是它居然有硬预热这个设定。
就像冬天开车不能一脚油门踩到底一样,它在刚开始的五百次迭代里只看热闹不记笔记,完全不管策略平均这回事。
等过了预热期,它才把那些真正有价值的策略挑出来做平均。这种做法一开始看让人觉得浪费时间,但实际跑起来效果出奇的好,在十个测试游戏里全面碾压了人类之前的最佳方案。
接着AI又去折腾PSRO这个门派,进化出了SHOR-PSRO。这个算法解决了以前门派管理的一个大痛点。
以前不管是在培养新徒弟还是考核老徒弟的时候,用的都是同一套死板的混合方法。但是SHOR-PSRO发现,训练和考核根本不应该是同一套逻辑。
登录/注册后继续阅读
立即登录/注册 >






























