
我要认证
2026-03-27
刚刚AI语音赛道再迎重磅玩家,法国顶尖AI公司Mistral开源了首款文本转语音(TTS)模型Voxtral,直接打破了行业内质TTS模型要么闭源付费、要么轻量模型效果拉胯的僵局。
这也是目前市面上少有的主打企业级应用的开源TTS模型,把轻量、高效、好用这几个点捏得太到位了。
开源地址:https://huggingface.co/mistralai/Voxtral-4B-TTS-2603
区别于当下市面上动辄百亿、千亿参数的臃肿AI模型,Voxtral将整体参数严控在40亿,属于妥妥的轻量型选手,却没有因为体量精简牺牲核心性能,真正做到了小身材大能量。
最惊艳的是它的运行门槛和响应速度,硬件适配性拉满,经过量化推理优化后,仅需3GB内存即可流畅运行。
不管是普通智能手机、老旧办公设备,还是企业自有低配服务器,都能轻松部署,完全不用额外投入高额硬件升级成本,彻底打破了高端TTS模型对高端算力的依赖。
在速度表现上,这款模型更是刷新行业水准。常规场景下,仅用10秒参考音频做音色复刻,处理500字符文本的语音生成,延迟低至70毫秒,几乎达到实时出音状态,全程无卡顿、无等待,使用体验丝滑度拉满
就算是首次音频传输,典型输入场景下延迟也仅90毫秒,语音生成速度更是达到实时语音的6倍,批量处理文本语音需求完全不费力。
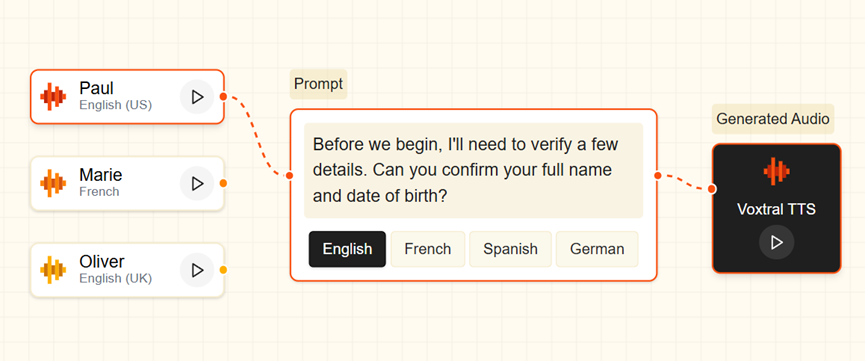
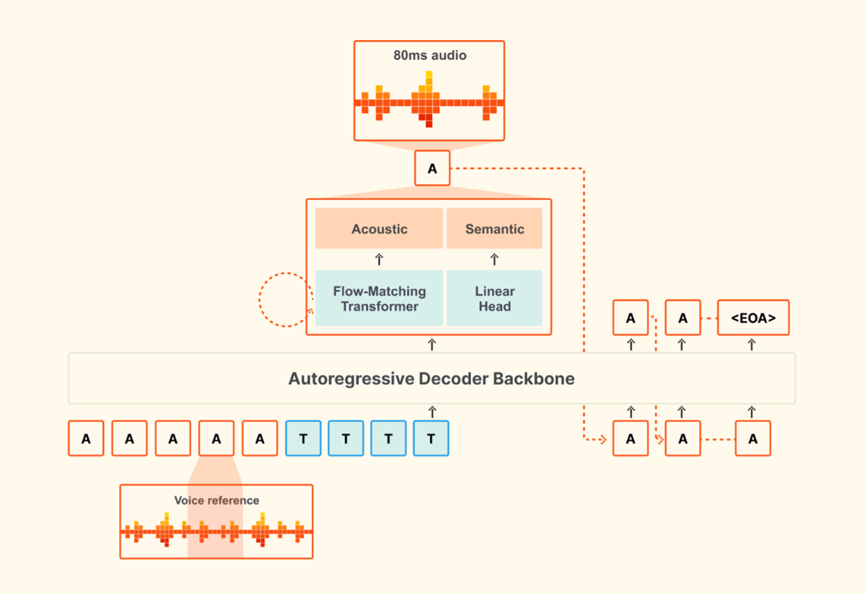
从技术架构来看,Voxtral是基于Mistral自研30亿参数基座模型优化而来,通过极致的组件复用性实现精简体量与强悍性能的平衡,整体架构分为三大核心模块。
第一部分是34亿参数的变换器解码主干网络,负责核心的文本到语音转换逻辑,保障转换精准度。
第二部分是3.9亿参数的流量匹配声学变换器,专门优化语音声学质感,让语音更贴近真人、更自然。
第三部分是企业自研3亿参数神经音频编解码器,大幅提升语音编码和解码效率,保障低延迟、高音质输出。三大模块配合顺畅,既避免了参数冗余,又最大化发挥模型性能。
其实Voxtral的实用性能远不止轻量快速,在语音生成质量和多语言适配方面,直接对标甚至超越头部闭源竞品。
语言覆盖层面,它原生支持德、英、法、西等9种语言,完美覆盖跨境商务、全球化服务的核心语言需求,无需额外训练即可直接使用。
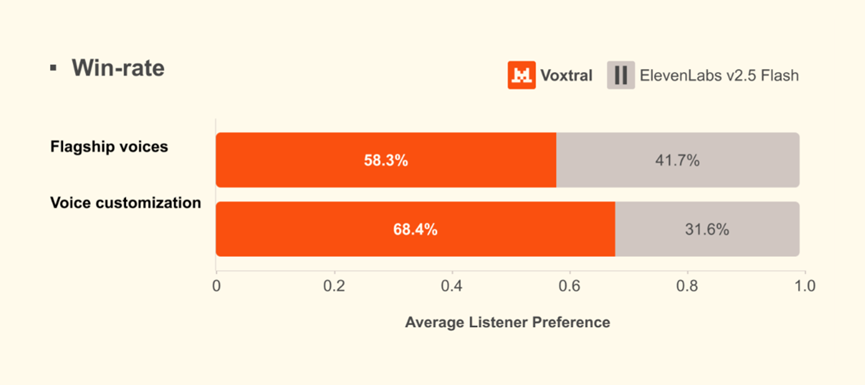
实测盲听对比中,Voxtral直接碾压ElevenLabs v2.5 Flash等同类型热门模型。
母语者打分数据极具说服力,多语言语音克隆场景偏好率高达68.4%,远超同类竞品。
登录/注册后继续阅读
立即登录/注册 >































