
我要认证
2026-03-27
今天凌晨,谷歌推出了专攻音频领域的新模型Gemini 3.1 Flash Live,直接让语音AI智能体迎来重磅突破,把AI语音交互的体验卷到了全新高度。
简单来说,这个新模型的核心目标就是让AI和人说话变得更自然、更靠谱,而且覆盖200多个国家和地区,开发者做产品、企业做客户服务、咱们普通用户日常使用,现在都能体验到。
其实这次谷歌推出的这个音频模型,就是把AI语音的体验做到了极致,响应速度比前代快了一大截,还能精准捕捉到人说话的语气情绪,不会再像以往有些AI那样。
不管你是开心分享还是有点烦躁提问,都用冷冰冰的统一语调回复,用它聊天,那种真人对话的感觉一下子就出来了。
开发者还能靠它打造语音AI智能体,处理复杂任务的能力也迎来了升级,咱们普通用户常用的搜索和Gemini实时交互功能,现在也能支持多语言交流,给出的回复也更贴合实际需求。
谷歌在安全方面也下足了功夫,这个模型生成的所有音频都加了专属水印,能从源头有效防范AI虚假音频的传播。
下面咱们直接看下这个模型的演示案例吧。
例如,你想组装一个家具但不知道如何搞,直接向AI提问就行。并且在安装的过程中还能与其实时交流。
也可以让AI帮助你识别一下物品,例如,找一把椅子直接让它帮你看看是什么样的。
对于做开发和企业端的朋友来说,这次的模型升级绝对是天降福利,整体性能拉满之后,不管是打造语音优先的智能体,还是规模化处理复杂的业务任务,靠谱程度都比之前提升了不止一个档次。
拿专业的复杂功能基准音频测试来说,这个模型开启深度推理模式后,能拿到90.8%的超高分数,直接把之前的Gemini2.5音频模型甩在了身后。
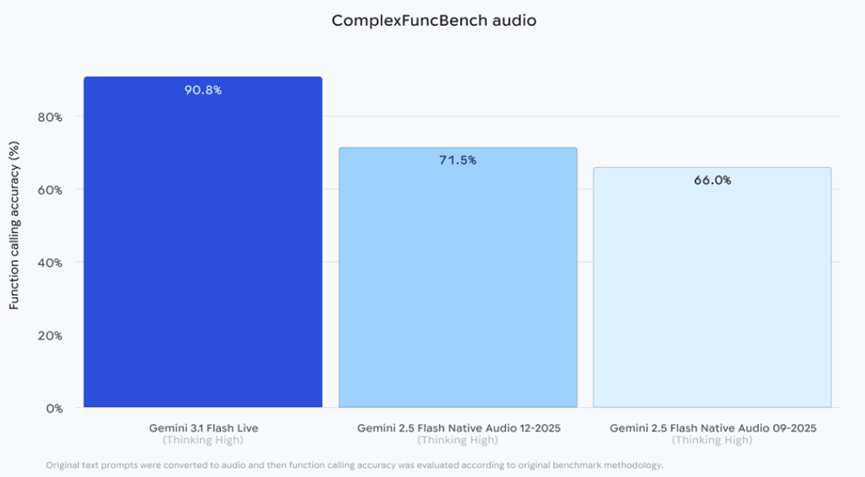
要知道去年12月的2.5版本才71.5%,9月的版本更是只有66%,这样的提升幅度,能直接看出谷歌的技术硬实力。
还有另一项大型基准音频测试,这个模型的语音AI智能体开启深度推理模式后,分数能达到95.9%。
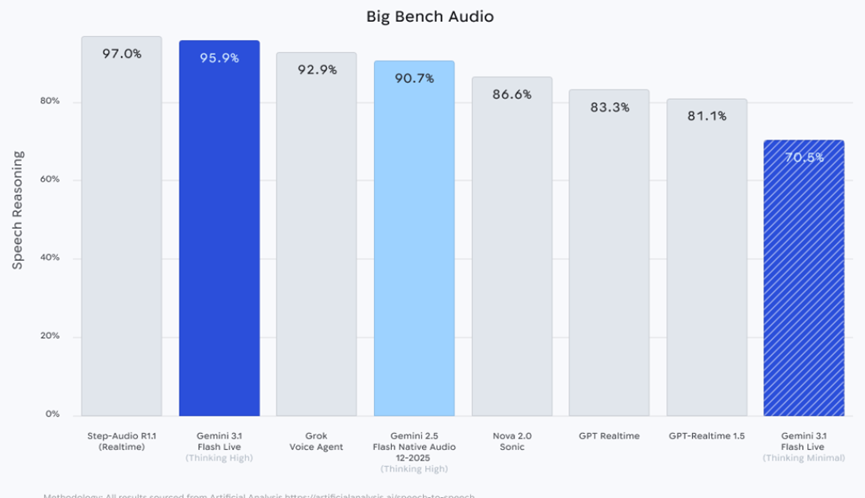
仅次于Step-AudioR1.1的实时模式,比Grok、SonicGPT等同类模型的分数都要高,就算开启简易推理模式,也能拿到81.1%的分数,日常开发使用完全绰绰有余。
而且在Scale AI的音频综合挑战赛中,这款模型依旧是领跑全场的存在,开启深度推理模式拿到了36.1%的分数。
把实时GPT1.5、通义千问3Omni30B还有GPT-4o的音频模型都甩在了后面。
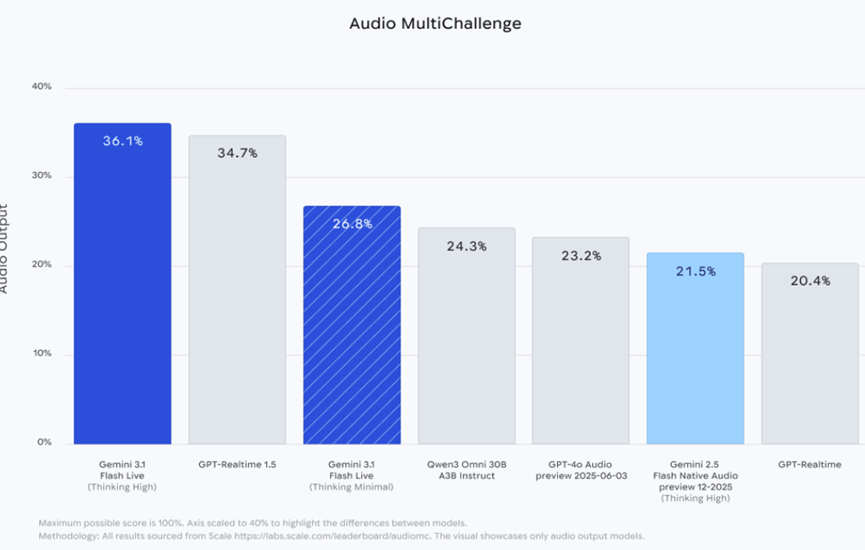
这个挑战赛可不是简单的纸上谈兵,专门考验模型在有外界干扰、有人说话停顿等真实音频场景中,执行复杂指令和长程推理的能力,能拿下第一,足以证明这个模型在实际使用中的表现有多稳。
除了超强的推理能力,这个模型对语气的理解能力也做了深度优化,在谷歌的客户体验企业版中使用时,能精准捕捉到人说话的音高、语速等细节。
要是察觉到用户说话带着烦躁或者困惑的情绪,模型还能动态调整自己的回应方式。
登录/注册后继续阅读
立即登录/注册 >































