
我要认证
2026-03-22
通常大模型智能体落地后很容易陷入静态困境,用户任务持续变化但模型能力原地踏步,会出现停服重训影响使用,积累的交互数据无法复用,跨任务知识也难以互通等问题。
介绍一个刚开源好用的MetaClaw,可以让部署在实际场景的AI智能体实现边用边进化,全程零停机。
还能通过双重机制加持,让普通模型性能追平顶尖模型,实测中端到端任务完成率暴涨8.25倍,文件检查完成率相对提升185%,真正破解了智能体落地进化的核心难题。

开源地址:https://github.com/aiming-lab/MetaClaw
咱们先唠唠现在的痛点,不然不知道这药方开得有多准。现在的适配方法大致分三类,但都有点瘸腿。
记忆类方法就像是囤积癖,存了一堆原始交互轨迹,看着挺多,其实全是废话,提炼不出能复用的行为逻辑。
Skills库类方法倒是把经验压缩成了指令,可它跟模型权重优化是脱节的,永远是个静态的外挂。
强化学习类方法听起来高大上,但要么只能在小范围离线练练,要么就被老数据里过时的奖励信号带沟里去,越练越抽抽。
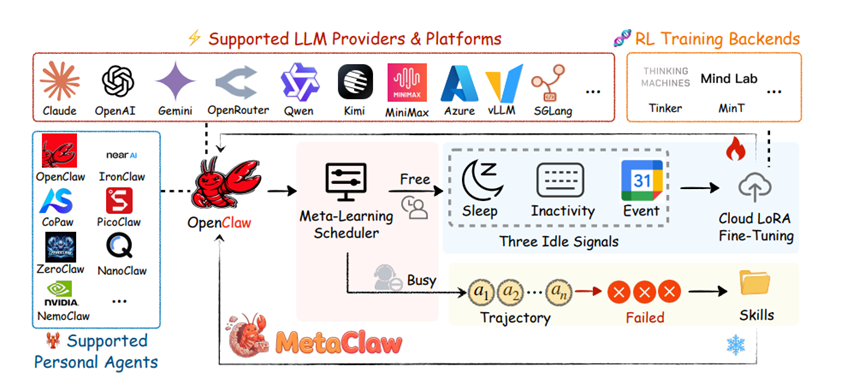
MetaClaw能管用核心就在于搞了个快慢结合的双重进化,而且脑子特别清醒,知道啥时候练、练啥数据。
其实这框架其实就像个元模型,底下是基础的大模型参数,上头挂了个能进化的Skills库。
Skills库像个随身老军师,推理的时候会把相关指令塞进提示词里,手把手教模型怎么干活。
咱们先说这个Skills驱动的快速适配,这玩意就像是给智能体打即时补丁,秒级生效,完全不需要动模型的底层参数。
智能体干活总有栽跟头的时候,以前栽了就栽了,现在它会把这些失败轨迹收集起来,扔给一个叫Skills进化器的大脑。
这个大脑分析完失败案例,立马就能提炼出避坑指南一样的新Skills,存进Skills库。下次再遇到类似情况,直接通过提示词注入,模型立马就知道怎么躲开。
但这光有外挂Skills还不够,底子也得练。这就得提那个机会主义策略优化。
它就是趁着用户空闲、不用模型的时候,悄悄在后台搞训练,完全不耽误正常业务。
有个特别聪明的调度器,会盯着用户配置的睡眠窗口、系统有没有活动,甚至还会看日历上的会议安排。只要发现你在忙别的,它就启动云LoRA微调,结合强化学习练内功。
这里头还有个特别精妙的设计,就是Skills生成版本控制。这事挺琐碎,但特关键。所有的交互轨迹都会被打上Skills库的版本标签,谁是支撑数据,谁是查询数据,分得清清楚楚。
支撑数据就是旧Skills库下栽跟头的记录,拿来生成新Skills,用完就扔;查询数据才是新Skills库上线后的交互轨迹,只有这类数据才有资格拿去训练模型权重。
每次Skills库一升级,缓冲区里那些过时的老数据立马清空。
登录/注册后继续阅读
立即登录/注册 >































