
我要认证
2026-03-22
最近计算机视觉圈迎来重磅突破,延世大学和成均馆大学联手研发出了3DreamBooth模型,攻克了3D视频生成的诸多行业痛点,把3D感知视频定制技术推到了新高度。
以往AI生成定制化3D视频,总逃不过视角变换主体变形、细节模糊、动作固化的问题。
而3DreamBooth不仅完美解决了这些难题,还打造了专属评估套件,让动态3D视频生成终于实现了保真又丝滑。
Github:https://github.com/Ko-Lani/3DreamBooth
咱们看下这个模型生成的案例。提示词:玛丽莲 梦露在好莱坞的化妆间里,面带微笑地亲吻着一个毛绒玩具,化妆镜前亮着灯泡。
戴着手套的手将飞行员太阳镜放在一个毛绒玩具上,冷蓝色和洋红色的节日彩灯,透过窗户可以看到白雪皑皑的城市。
一台抓娃娃机抓住一个毛绒玩具,并缓慢地将其旋转360°,背景是霓虹街机灯光。
看完这些超真是的3D视频案例,咱们聊聊早期3D视频生成有哪些局限性。
早期的文字定制法,受限于文字的信息表达能力,根本抓不住物体的精细纹理和复杂结构。
后来出现的视觉适配器,能保住2D图像的细节,可应用到视频中,一切换视角就露馅。
再加上多视角视频数据集的稀缺,用少量视频微调模型,很容易让模型只记住固定动作,换个运动方式就无法适配。
简单来说,过去的AI只认识物体的平面视角,没有建立立体认知,自然做不出视角一致的动态3D视频。
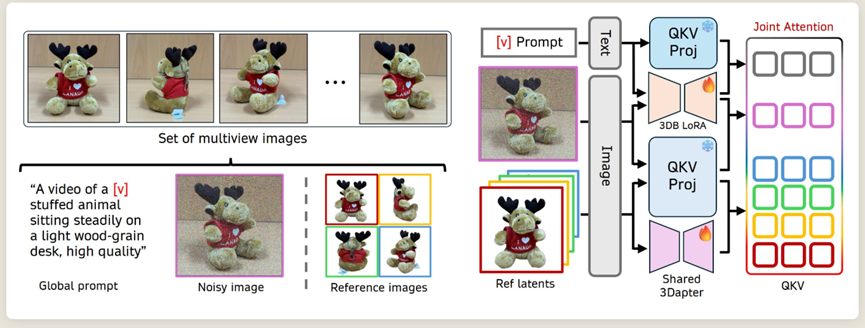
而3DreamBooth框架的核心,就是靠3DreamBooth和3Dapter两个模块协同工作,把物体的空间结构和视频的时间运动拆分开来学习,从根源上解决了此前的技术难题。
其中3DreamBooth的核心作用,是给模型刻入物体的3D记忆,同时还不会让模型记混动作。
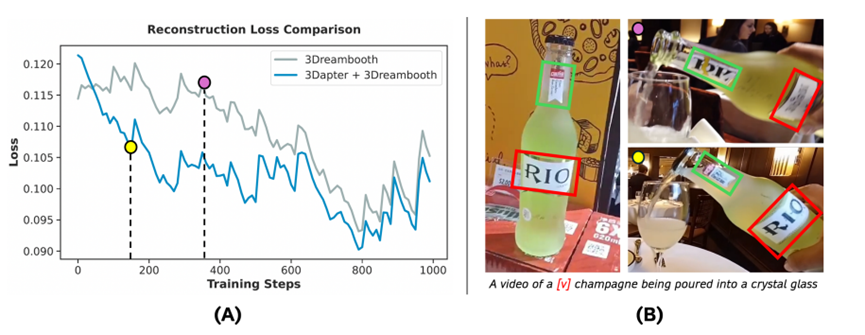
最巧妙的设计,是利用单帧训练方式分离3D特征和动态特征,研究团队发现物体的核心特征都是空间属性,和运动状态无关。
而视频扩散模型有个特性,仅输入单帧图片时,时间注意力机制会自动失效,所有学习都会聚焦在空间特征上,无需修改模型结构,就能实现空间和时间特征的自然分离。
训练时,只需将物体不同角度的静态照片当作单帧视频喂给模型,搭配含专属标识V和物体类别的固定提示词,让模型把物体各角度的空间特征都融入标识V中。
同时借助LoRA低秩适配技术,不改动模型原有的预训练参数,仅增加少量可训练权重,既保留模型原本的动态生成能力,又把物体的3D结构刻入其中。
这个模块无需依赖稀有的多视角视频数据集,靠静态照片就能完成训练,充分利用了预训练视频模型本身的3D感知能力。
3Dapter是一个视觉条件模块,直接将物体的图像特征输入模型,跳过文字中转环节,让信息传递更直接。
它的训练分两步走,先通过大量纯白背景和实景配对的物体图做单视角预训练,让模块学会从单张图中抓取核心特征,再和3DreamBooth联合训练,针对具体物体做适配。
联合训练时会选取物体360度无死角的多视角图,去掉背景后喂给3Dapter,所有视角图由同一个3Dapter处理,既保证特征一致性,又控制参数数量。
而且模型会为每个视角图分配专属时序索引,防止特征混淆,还能自动筛选参考图,生成某一视角画面时,只提取最相关的几何特征,让生成效果更精准。
登录/注册后继续阅读
立即登录/注册 >































