
我要认证
2026-03-20
干数据这行的朋友,一定深有体会,我们总说着要训练模型、挖掘洞察、搭建酷炫的可视化仪表盘,可现实却是,大部分时间都耗在了和脏数据死磕。还没开始,就被一堆乱七八糟的原始数据耗干了心情。
手动清洗?那可太要命了,不仅枯燥到让人怀疑人生,还特别容易漏掉细节、引入新错误。而且每次换一个数据集,又得从头来一遍,根本没法规模化。
别怕,今天给大家介绍5 个简单但超实用的神级Python自动化清洗脚本,专治各种脏数据。

1、缺失值处理器
你的数据集到处都是缺失值,有些列的完整度为90%,而有些列的数据则十分稀疏。
你需要决定如何处理每一列的缺失值:删除行、用均值填充、对时间序列采用前向填充,或是使用更复杂的插补方法。手动处理每一列既繁琐又容易出现不一致。
脚本功能
自动分析整个数据集中缺失值的分布模式,根据数据类型和缺失模式推荐合适的处理策略,并应用选定的插补方法。生成详细报告,说明缺失值的位置及处理方式。
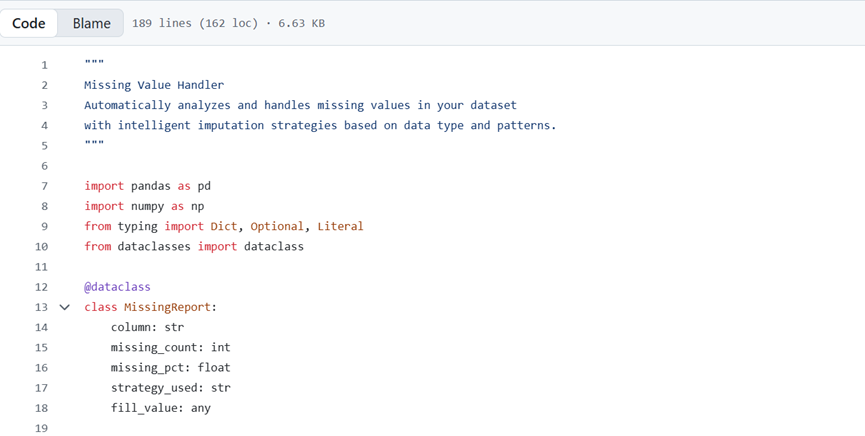
工作原理
脚本扫描所有列,计算缺失值比例和分布模式,确定数据类型(数值型、分类型、日期时间型),并应用相应的处理策略:
数值型数据:使用均值、中位数填充
分类型数据:使用众数填充
时间序列数据:使用插值法填充
该脚本能区分并差异化处理完全随机缺失(MCAR)、随机缺失(MAR)和非随机缺失(MNAR)模式,并记录所有更改,确保结果可重现。
完整代码:https://github.com/balapriyac/data-science-tutorials/blob/main/useful-python-scripts-for-data-cleaning/missing_value_handler.py
2.、重复记录检测与解决器
数据中存在重复记录,但并非都是完全匹配的情况。有时是同一客户的姓名拼写略有不同,有时是同一笔交易被记录了两次但存在细微差异。
要找出这些模糊重复项并决定保留哪条记录,需要手动检查数千行数据。
脚本功能
通过可配置的匹配规则识别完全重复和模糊重复记录。将相似记录分组,计算相似度得分,并根据你定义的存活规则,如保留最新记录、保留最完整记录等。要么标记重复项供人工审核,要么自动合并记录。
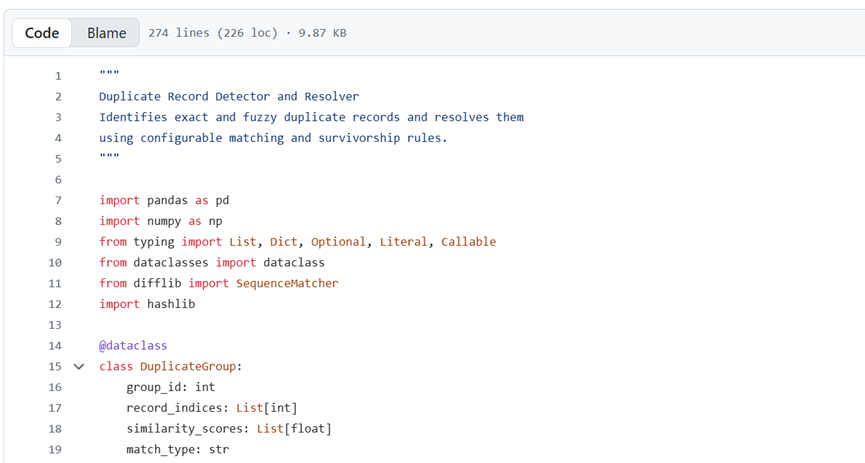
工作原理
脚本首先使用基于哈希的比较快速查找完全重复项,然后利用编辑距离和杰罗 - 温克勒距离等模糊匹配算法,对关键字段进行比对以查找近似重复项。
将记录聚类为重复组,存活规则决定合并时保留哪些值。生成详细报告,展示所有找到的重复组及采取的处理措施。
完整代码:https://github.com/balapriyac/data-science-tutorials/blob/main/useful-python-scripts-for-data-cleaning/duplicate_detector.py
3、数据类型修正与标准化器
导入 CSV 文件后,所有数据都变成了字符串格式;日期存在五种不同的格式;
数值中包含货币符号和千位分隔符,同一列中的布尔值有多种表示方式。要获得一致的数据类型,需要为每个杂乱的列编写自定义解析逻辑。
脚本功能
自动检测每列的目标数据类型,标准化格式,并将所有数据转换为合适的类型。处理多种格式的日期、清理数值型字符串、规范化布尔值表示,并验证转换结果。提供转换报告,说明更改内容。
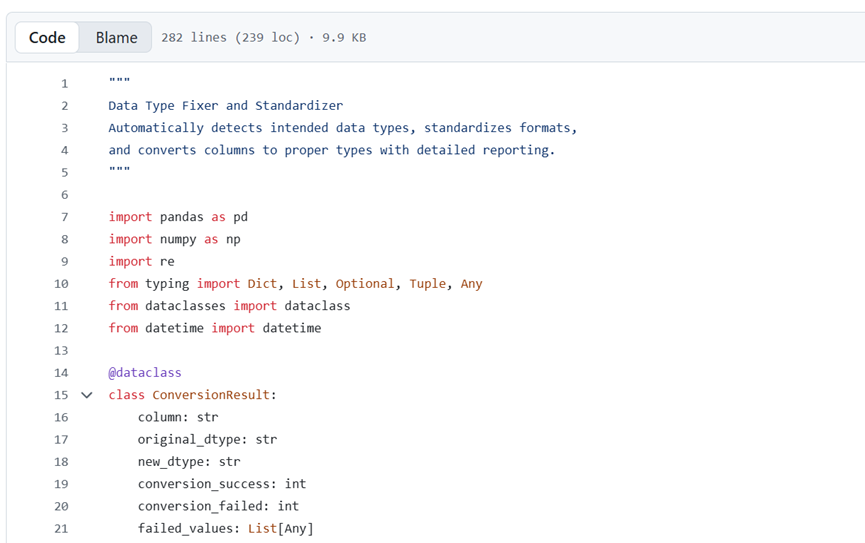
工作原理
脚本对每列的数值进行抽样,通过模式匹配和启发式算法推断目标数据类型,然后应用相应的解析方法:使用 dateutil 进行灵活的日期解析、使用正则表达式提取数值、使用映射字典规范化布尔值。记录转换失败的情况及问题数值,供人工审核。
完整代码:https://github.com/balapriyac/data-science-tutorials/blob/main/useful-python-scripts-for-data-cleaning/datatype_fixer.py
4、异常值检测器
数值型数据中存在会破坏分析结果的异常值。有些是数据录入错误,有些是需要保留的合理极值,还有些则难以界定。
你需要识别这些异常值、了解其影响,并决定处理方式,缩尾处理、封顶处理、删除或标记供审核。
脚本功能
使用四分位距IQR、Z 分数、孤立森林等多种统计方法检测异常值,可视化异常值的分布及影响,并应用可配置的处理策略。区分单变量异常值和多变量异常值。生成报告,展示异常值数量、具体数值及处理方式。
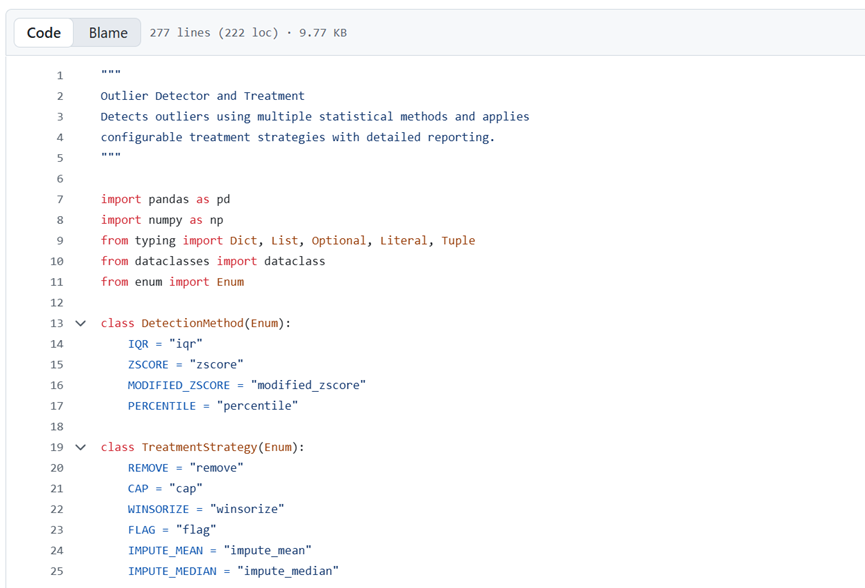
工作原理
登录/注册后继续阅读
立即登录/注册 >































