
我要认证
2026-03-15
普林斯顿大学的研究团队开源了一个非常强的训练框架OpenClaw-RL。
这个项目非常简单直接,就是让OpenClaw通过跟你日常聊天的过程自动学习进化。
你不需要标注数据,不需要准备训练集,甚至不需要停下来专门训练,正常使用它就能在后台默默不断优化自己能力。
当然除了OpenClaw,其他别的AI Agent智能体同样适用于这个框架。

开源地址:https://github.com/Gen-Verse/OpenClaw-RL
市面上大多数强化学习框架都挺高冷的,要求你先收集一堆数据,整理成特定格式,然后批量训练。
而OpenClaw-RL完全反其道而行,把整个流程打散成四个独立的异步模块,模型服务、数据收集、评分评估、策略训练各干各的互不干扰。
这意味着你在用模型的时候,训练在后台跑着,评分也在同时进行,一切都是实时流动的。
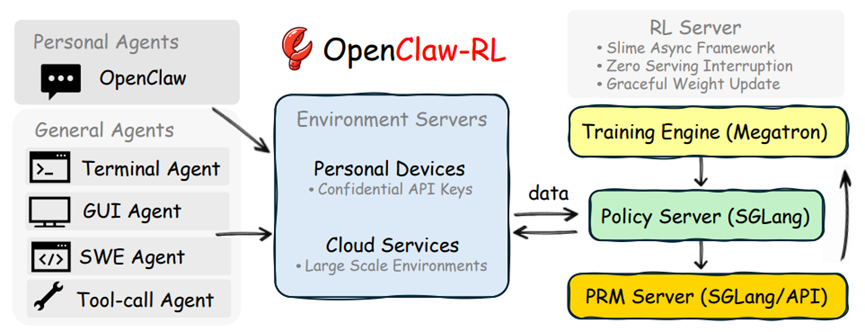
例如,你和OpenClaw聊天、用它解决问题的同时,后台已经在自动整理对话数据、用评估模型打分、计算奖励优化模型了。
再也不用经历训练和使用二选一的尴尬,真正实现边用边训,越用越顺手。
最让人惊喜的是它的自动化数据处理能力,彻底告别手动标注数据的痛苦。
框架能自动把你和智能体的多轮对话整理成有会话感知的训练轨迹,还能智能区分哪些对话内容能用来训练、哪些是无需训练的辅助内容。
同时它会把你后续的反馈、环境的回应甚至工具的执行结果,都当成天然的训练信号,自动用评估模型做打分。
还会在需要的时候通过多数投票让评分更精准,最后把这些信号转换成模型能识别的梯度,从反馈到训练素材的生成,全程不用人工干预
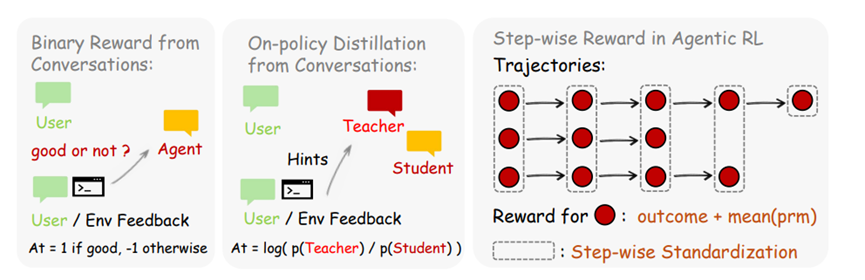
另外 OpenClaw-RL 还集成了三种优化方法,不管你是只给简单的好坏这类隐性反馈,还是给出具体的文字修正这类显性反馈,都能找到对应的优化方式。
第一种是二值强化学习,用一个过程奖励模型给每轮对话打分,然后基于这个分数进行策略优化。
第二种是在线策略蒸馏,当后续状态能提供有价值的事后信息时,让评分模型生成文字提示,这个提示会增强原始问题,形成一个更聪明的教师模型。
登录/注册后继续阅读
立即登录/注册 >































