
我要认证
2026-03-15
做技术开发的朋友对OCR识别的痛点一定深有体会,规规矩矩的印刷体还好说,可碰到复杂表格、专业公式、公章印章或是手写内容,多数模型直接拉胯。
介绍一个智谱AI开源非常好用的GLM-OCR,目前在HuggingFace上下载量狂飙260万,同时在多项权威测评中霸榜第一,成为中文OCR领域的大黑马。
这款轻量级多模态OCR模型,把识别精度、推理速度和部署便捷性做到了兼顾,不管是企业级业务落地还是个人开发使用,适配度都拉满。
开源地址:https://huggingface.co/zai-org/GLM-OCR
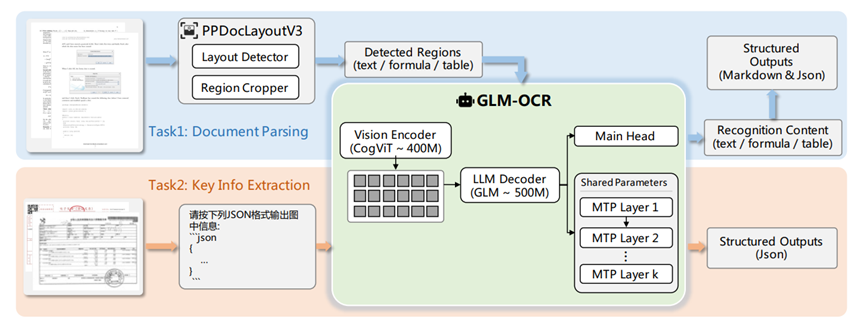
从核心结构来看,GLM-OCR有点像一个分工明确的专业团队,先是由在海量图文数据中预训练的CogViT视觉编码器捕捉图像特征。
再通过轻量级跨模态连接器完成视觉与语言信息的无缝对接,最后由GLM-0.5B语言解码器将视觉信息转化为准确文字。
同时它还结合了PP-DocLayout-V3的两阶段处理流程,先做布局分析再进行并行识别,再奇葩的文档排版都能梳理清晰,彻底解决了传统OCR识别混乱、漏识别的问题。
能在短时间内圈粉无数,下载量突破260万,GLM-OCR的核心竞争力主要有四个方面,每一个都精准踩中了实际使用的痛点。
首先是性能登顶行业顶尖,在OmniDocBenchV1.5权威文档理解测评中,它拿下94.62的高分稳居第一,公式识别、表格识别、信息提取等主流测评中,也都是第一梯队表现,碾压不少大厂通用大模型的OCR能力。
其次是专为真实场景优化,实际工作中的复杂表格、代码密集型文档、带公章的正式文件,这些传统OCR的重灾区,都是GLM-OCR的强项,复杂布局下依然能保持稳定的识别效果。
再者是轻量高效易部署,整个模型仅0.9B参数量,和动辄几十上百B的大模型比堪称轻量,却支持vLLM、SGLang、Ollama多种部署方式。
能大幅降低推理延迟和计算成本,高并发企业服务和边缘设备部署都能轻松扛住。
最后是全开源好上手,模型完全开源,配套完整的SDK和推理工具链,安装简单一行命令调用,和现有生产流水线整合也十分顺滑,技术团队不用投入大量时间二次开发,就能快速落地使用。
咱们再重点详细说下GLM-OCR在主流评测平台的数据。文档解析方面,OmniDocBenchv 1.5测评中它拿到94.6的分数,稳居专用视觉语言模型第一位。
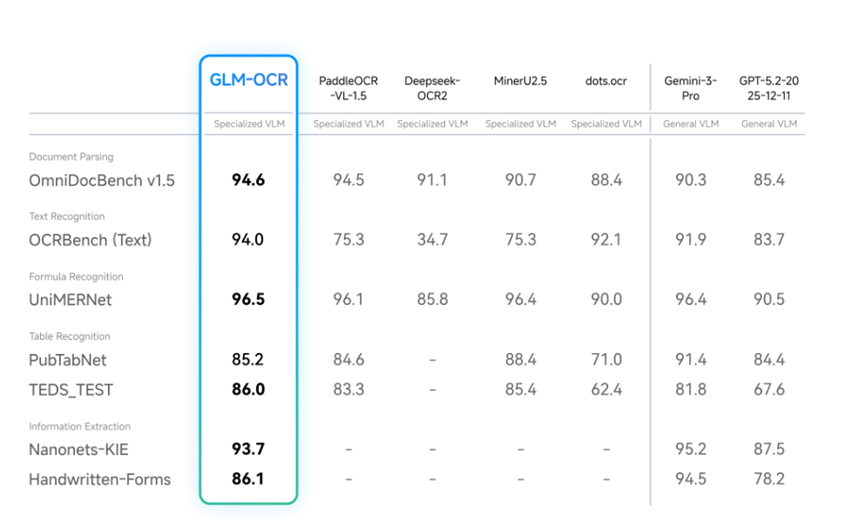
文本识别在OCRBench测评中飙至94.0,远超同类模型;公式识别更是强项,UniMERNet测评中96.5的分数几乎触到行业天花板,复杂学术公式也能精准识别。
表格识别虽在标准测评PubTabNet中略逊MinerU2.5。但在真实场景表格识别中拿下91.5的高分,远超同类模型,毕竟真实业务中的表格,远比测评标准表格复杂。
针对真实业务的高频场景,GLM-OCR的表现同样亮眼,代码识别84.7、印章识别90.5、票据信息提取94.5,能看出它的优化并非为了测评,而是真正适配实际使用。
登录/注册后继续阅读
立即登录/注册 >































