
我要认证
2026-01-31
最近Robbyant团队搞了个大新闻,他们开源了一个叫做LingBot-World的世界模拟器。
这玩意可不简单,它不是那种你丢给它一句文字它就给你生成个几秒钟短视频的普通工具。
而是一个能够模拟真实物理世界动态、并且让你在这个世界里实时互动的超级AI系统。

开源地址:https://huggingface.co/collections/robbyant/lingbot-world
Github:https://github.com/Robbyant/lingbot-world
例如,只需要几句提示词就能生成一个让你随意游玩的故宫。
游览雄伟壮丽的万里长城也没问题。
直接生成一分钟的玄幻世界也是刚刚的。
甚至在操控性、光影、场景实时生成方面比谷歌的王牌世界模型Genie 3更好。
咱们先说说现在的世界模型生成到底卡在哪了。虽然大家在网上看到那些AI生成的视频越来越逼真,光影效果、纹理细节简直跟电影大片一样,但说白了,这些模型本质上还是在做梦。
它们是靠着统计概率,猜这一帧后面大概率是哪一帧,根本没有真正理解发生了什么。
所以你经常会看到视频里走着走着人物突然变形,或者手里的杯子莫名其妙消失了。这就是缺乏因果律和物体恒存性的表现。
而LingBot-World就用它的三板斧来解决这些难题。
要想教AI懂物理,首先得有好的教材,也就是数据。但是网上现成的视频大多是被动的,只有画面没有动作信号,就像看一部没有字幕和操作记录的电影,很难学懂怎么去控制里面的东西。
于是LingBot-World搞了一个极其强悍的数据引擎,简直像个不知疲倦的数据大厨。
不光去网上搜集各种高质量的普通视频,从第一人称的走路视角到第三人称的开车视角全都收录。还专门搞了个游戏数据采集平台,直接录制游戏里的画面。
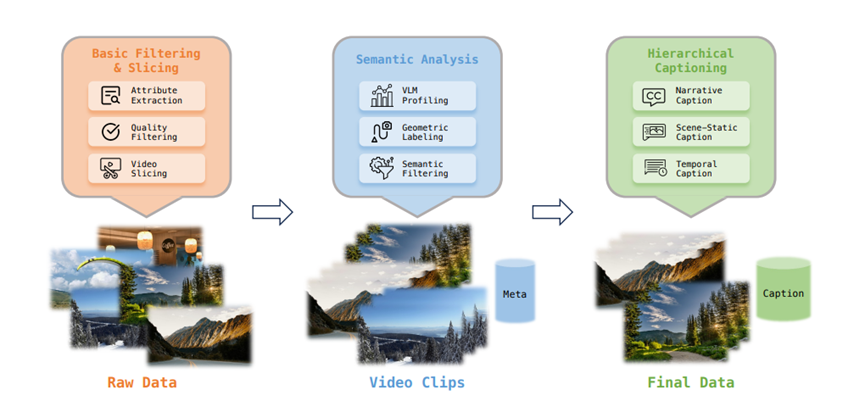
数据采回来之后,不能直接扔给模型,得先好好洗一洗,这就是数据剖析环节。系统会像个严格的质检员,把那些模糊不清、时长太短的视频统统踢掉。然后它利用各种算法,把长视频切成一段段适合训练的小片段。
对于那些没有标注相机位置数据的普通视频,系统还能用AI算法把相机的姿态算出来,补全信息。这就好比给一段旧视频配上了3D空间坐标。
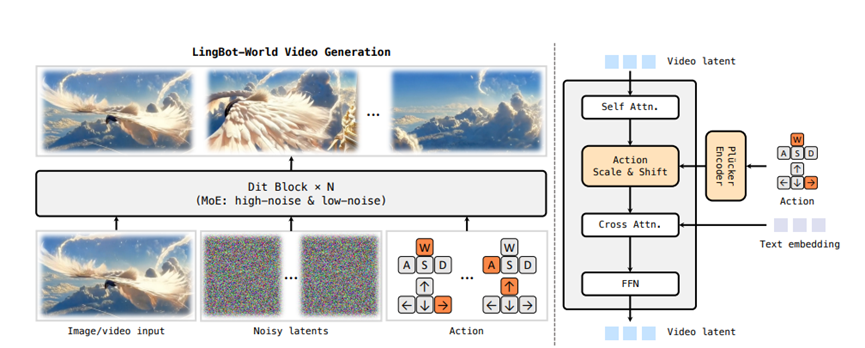
有了这些精心准备的数据,接下来就是最关键的训练环节了。这个过程就像教一个学生,从学会画画到学会拍电影,再到学会做游戏导演,分了三个阶段。
第一个阶段是打基础。团队直接用了一个已经练得很好的14B参数的大模型作为底座,这就好比找了个艺术造诣极高的画师来教学生。
这个阶段主要让AI学会怎么画出高逼真度、纹理细腻的画面,理解基本的时空关系,给它打下坚实的视觉基础。这时候它还不懂怎么交互,但已经能生成非常漂亮的静态视频了。
第二个阶段是注入灵魂,也就是中间训练。在这个阶段,模型开始学习世界知识和动作控制。为了处理复杂的世界,他们用了一个叫混合专家架构的技术。
登录/注册后继续阅读
立即登录/注册 >































