
我要认证
2026-01-26
现在AI语音很火,各种语音AI助手遍地开花。但作为开发者,你是不是经常遇到这些让人抓狂的情况,想做TTS文本转语音,结果安装个OpenAI Whisper都要折腾半天。
想用自己的Mac训练语音模型,却因为依赖一堆CPU框架慢得像蜗牛,想集成语音功能到iOS或者macOS应用,却找不到合适的原生解决方案。
为大家介绍Github今天最热门的开源MLX-Audio来解决这个难题。
开源地址:https://github.com/Blaizzy/mlx-audio
MLX-Audio是一个专门为AppleSilicon打造的全能语音处理库,就像你的Mac上有了一位随身语音魔法师,能把文本转成语音、把语音转成文本,甚至直接进行语音到语音的转换,所有这些操作都在Apple的MLX框架上运行,完美榨干M1、M2、M3、M4芯片的性能。
让你的Mac能像超级计算机一样处理语音任务,高效快速,全部在本地运行,隐私安全有保障。
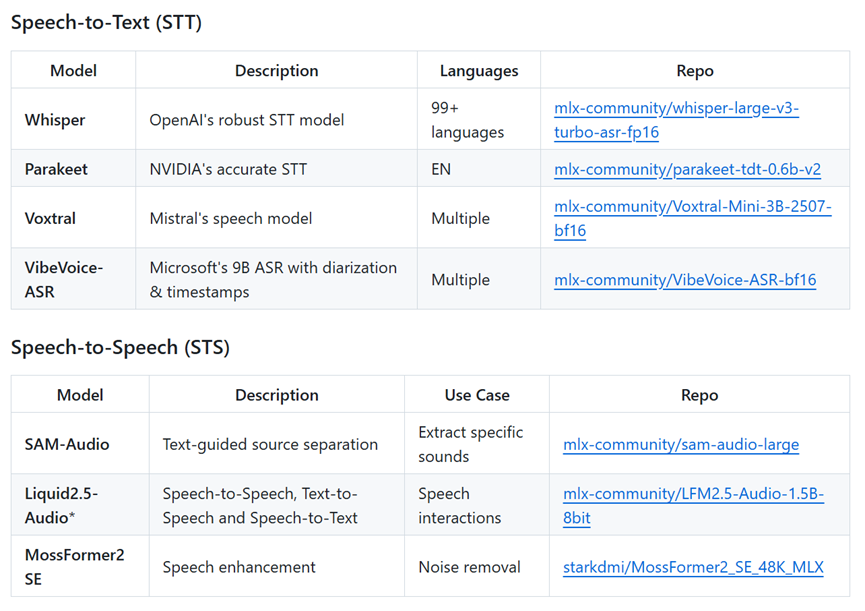
MLX-Audio最核心的能力是三合一语音引擎,也就是大家常说的TTS、STT和STS,TTS可以把文字变成高质量的语音,支持多种语言和口音,STT能把语音转录成文字,支持99种以上的语言。

STS则可以直接实现语音到语音的转换,比如翻译或者变声,你不用再东拼西凑找好几个不同的工具了,一个库就能搞定所有语音需求,减少依赖也降低了项目复杂度。
更重要的是针对Apple Silicon做了极致优化,推理速度专门针对M系列芯片调校,还支持量化模型从3bit到8bit,能进一步压缩内存占用。
甚至提供原生的Swift包,可以直接集成到iOS或者macOS应用里,实际用起来速度能提升5—10倍,以前跑一个小时的任务现在可能10分钟就搞定了,而且全部在本地运行,数据根本不会离开你的设备,隐私百分百安全。
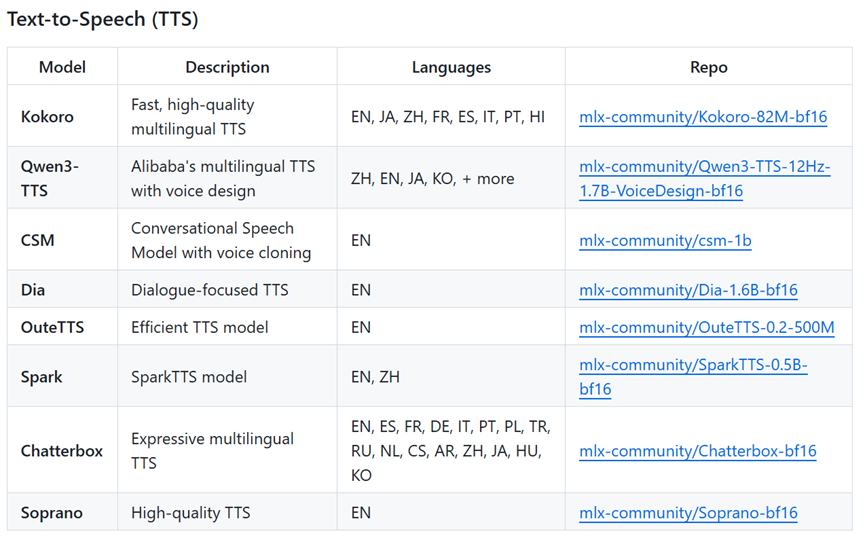
模型生态也特别丰富,TTS方面有Kokoro这种带54种预设声音的模型,还支持阿里巴巴的Qwen3-TTS多模型支持以及OuteTTS等等。
STT有大家熟悉的Whisper、Parakeet、VibeVoice-ASR,STS则有SAM-Audio声源分离和Liquid2.5-Audio等。
你不需要自己从头训练模型,拿来就能用,而且模型还会持续更新,总有最新最厉害的选择。
登录/注册后继续阅读
立即登录/注册 >































