
我要认证
2026-01-26
咱们平时拍的照片或者视频,其实视野特别窄,就像拿个望远镜看世界一样,想把它变成360度全景,让体验变得沉浸并不容易。
以前的老方法有个大毛病,它们非得知道当时相机是怎么摆的,比如镜头角度多大,是不是歪着拍的,这叫相机元数据。
这要是拍个照片还好说,如果是网上随便找个视频,这些信息根本没有,或者根本不准,以前的模型立马就抓瞎,生成出来的东西惨不忍睹。
谷歌DeepMind跟几个高校的大佬们联手搞了个创新颠覆模型360Anything。看名字就特别霸气,所有任何东西都能给你干成360度全景。

论文地址:https://arxiv.org/abs/2601.16192
项目地址:https://360anything.github.io/
咱们先说说最头疼的那个相机信息问题。以前的思路特别死板,非要把一张窄视角的照片硬生生投影到全景画布上,位置必须对得严丝合缝。
这就像拼图必须找到唯一的缺口。这就要求你必须极其精确地知道这张照片是从哪个角度拍的。
360Anything完全换了个路子,它把照片和全景图都当成是一串乱码一样的序列,直接丢给扩散大模型。
这模型就像个绝顶聪明的侦探,通过全盘审视这些乱码,自己就能琢磨出来,哦,原来这张窄图应该是这片全景的右下角,或者左边这块。
这就不需要任何人告诉它相机参数了,完全靠它自己吃透了海量数据后总结出来的经验,这不就省去了找相机信息的麻烦吗,拿来就能用。

再有个特别讨厌的毛病,就是生成的全景图左右两边拼在一起的时候,总有一条明显的接缝,特别破坏体验。
以前大家都是在图生成出来以后,想各种办法去修补,或者旋转一下图片糊弄过去。但360Anything的这帮人居然追根溯源,找到了罪魁祸首。
原来是因为编码图片的时候用的那个工具,在边缘喜欢补零,就像画画在边缘留了白,导致模型理解的时候出了偏差。他们想了个特别巧妙的招,叫循环潜在编码。
简单来说,就是在给图片编码前,先把左边缘的一块挪到最右边去,把右边缘的一块挪到最左边来,让它首尾相连。这一招简直是四两拨千斤,直接从根源上把那个接缝给抹平了,生成出来的全景图顺滑得像没有尽头一样。
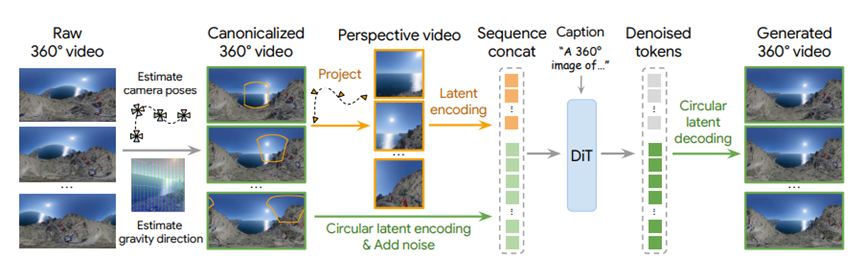
为了让生成的视频看着更舒服,他们还加了个特别人性化的设计。咱们拍视频难免手抖或者乱转,生成出来的全景如果也是歪歪扭扭的,看着多晕啊。他们就在训练数据上下功夫,把所有视频都矫正过来,强制重力方向垂直向下。
不管你输入的视频是仰着拍还是歪着拍,它给你生成的全景永远是正的,就像把世界摆正了一样。这种设计让视频看起来特别稳,时间长了也不容易晕。
为了全面验证360Anything的性能,研究团队做了涵盖全景图像生成、全景视频生成、相机参数估计和3D场景重建的多维度实验,通过定量指标和定性分析,和当前主流方法进行了全面对比,结果全部都是最强的。
在LavalIndoor和SUN360两个数据集上,360Anything的表现可以说是碾压式领先。
在LavalIndoor数据集上,它的FID是8.0,比当前最优的CubeDiff低了15.8%;KID是0.22×10²,也低于CubeDiff的0.32×10²;特别是FAED仅为9.8,比CubeDiff的18.4降低了46.7%,几乎减半。
在SUN360数据集上,360Anything的FID为22.4,KID为1.27×10²,CLIP-FID为7.3,都优于CubeDiff;
FAED更是降到了3.8,比CubeDiff降低了50%;CLIP-score达到28.07,也是所有方法中最高的,说明它的文本对齐能力更强。
登录/注册后继续阅读
立即登录/注册 >































