
我要认证
2026-01-22
视频动作识别一直是AI迈向物理世界的硬骨头,无论是智能家居理解你的手势指令,还是机器人学习装配零件,都离不开对动作的精准捕捉。
可长期以来这块领域一直卡在数据的瓶颈上,多数数据集太小根本不够模型吃饱,或者覆盖面太窄只会做饭或者玩具组装,训练出来的模型在真实场景里一用就露怯。
Meta FAIR、中国香港科技大学、阿姆斯特丹大学等机构联合开源了一个全球最大的视觉训练数据集Action100M。

开源地址:https://github.com/facebookresearch/Action100M
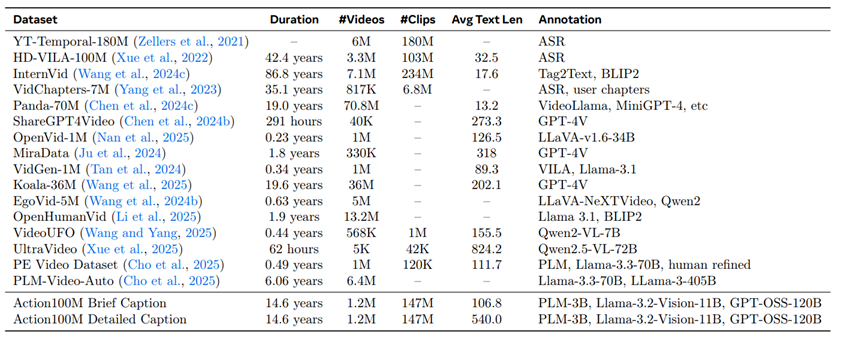
他们拿来做基础的素材其实很朴素,就是从网上爬了大约120万条教学视频,总时长加起来竟然有14年半那么长。光有视频当然不够,关键是怎么把这么庞大的视频内容变成机器能懂的结构化标注。
团队设计了一套全自动化的流水线,这套流水线就像一条智能工厂的生产线,把原始视频一步步加工成高质量的训练数据。
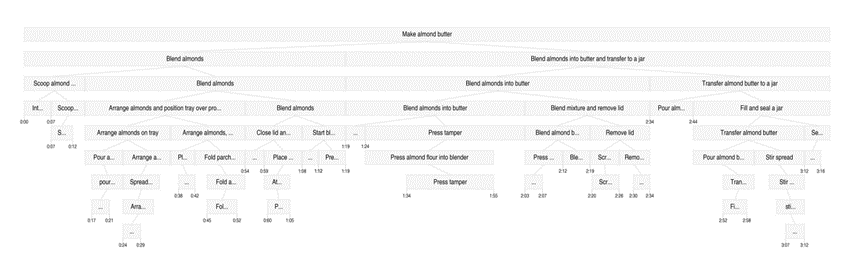
第一步是先把连续的视频切成有意义的片段,这里用了一个叫V-JEPA 2的视觉编码器先把视频帧的特征提取出来,然后用了层级凝聚聚类的方法给视频切分。
这个切分不是傻傻地按固定时长乱砍,而是会观察视觉内容的连贯性,把动作相关联的部分聚在一起,最终形成一棵层级树。
底层是很细碎的原子动作,上层是宏观的步骤流程,整个过程就像给视频做了一次智能切片,同时保留了动作的内在逻辑结构。
有了时间分片之后,接下来就是给每个片段生成文字描述。这里用了两套互补的策略,对于最细碎的小片段,他们取中间的关键帧让Llama-3.2-Vision模型看着图片写详细说明,重点捕捉空间的细节。
对于较长的片段,就均匀采样三十二帧让Perception-LM-3B模型看着视频写描述,重点讲时间的动态变化。
这样一来,每个片段都会拿到一份既精细又有层次的文字记录,这些文字记录按照前面的层级树组织起来,就构成了一个叫Tree-of-Captions的结构,就像是给视频每个层次都配上了一双能写会说的眼睛。
生成了一堆字幕描述之后,最关键的一步是怎么把这些散乱的信息聚合起来变成真正有用的标注。这里派出了GPT-OSS-120B这个大模型来做最后的信息提炼。
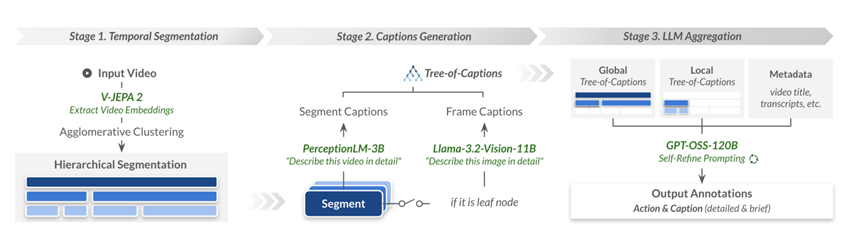
针对每个节点,它需要提取出五大核心内容,包括动作的简短描述、动作的详细说明、谁在执行动作、视频的简短字幕和详细字幕。
为了防止大模型产生幻觉或者胡编乱造,团队设计了三轮自我优化的流程,让模型反复审视自己之前写的东西,对比原始上下文,不断修正错误和不一致的地方,确保最终输出的标注既准确又靠谱。
整个过程处理下来,一共生成了接近一点五亿个片段级标注,文字量高达两百一十三亿个英文单词,存储起来占用了两百多GB的磁盘空间,算下来光做数据处理就耗了一百多万小时的V100 GPU算力和三十万小时的H100、H200算力,这工程量确实惊人。
这么折腾出来的数据集,规模和质量自然和以前那些完全不在一个层级。先说规模,以前的COIN数据集只有四万多个动作片段,YouCook2更少,也就两万个出头,完全撑不起来现代大规模模型的需求。
Action100M直接冲到了1.47亿个片段,数量级上的跨越就是降维打击。
登录/注册后继续阅读
立即登录/注册 >































