
我要认证
2026-01-22
在计算机视觉领域,3D重建一直是个大难题。静态场景重建得又快又准,可遇到动态的东西比如奔跑的人、移动的机器人,就瞬间没了脾气。
牛津大学VGG团队开源了V-DPM模型解决了这个难题。不用从零开始训练新模型,就靠给现成的静态3D重建模型加个小插件,就能让它精准捕捉动态场景的4D信息,连物体的运动轨迹和相机参数都能一并算出来。

开源地址:https://github.com/eldar/vdpm
说到这可能有人会问,以前难道没人尝试过动态重建吗?
当然有,但之前的办法要么就是拿2D跟踪器硬凑,要么就是只能处理两张图片,真正到了长视频或者多相机拍摄的情况,要么效果一般,要么计算量大得离谱。
想象一下,如果你想把一段十秒钟的视频完整还原成三维动画,按老办法可能需要算的点云数据量会像滚雪球一样越滚越大,普通显卡根本吃不消。
V-DPM聪明就聪明在它没有重复造轮子,而是把一个已经做得很好的静态模型给巧妙地改造成动态版本。
这个被选中的叫VGGT,本来是个专门做静态多视图重建的模型,VGG团队琢磨着既然它已经学会了怎么从不同角度把静态场景看明白,那只要给它加上时间的维度,是不是就能把动态场景也搞定了。
整个改造过程说得通俗点,就像是教一个只会画画的人学做动画。原来的VGGT拿到几张照片,能算出每个像素在三维空间里的位置,这个位置是固定的,不管你什么时候拍它都在那里。
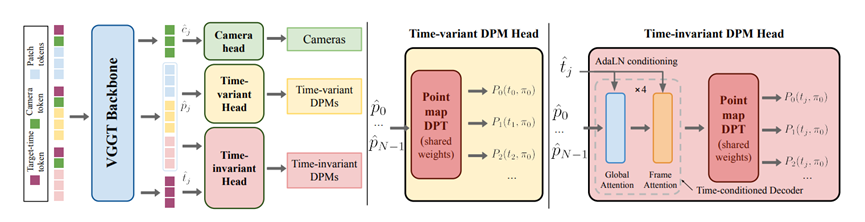
V-DPM的做法是让它不再只输出一个固定的位置,而是给每个像素算出它在不同时间点的位置。
这样一来,通过对比同一像素在不同时刻的三维坐标,自然而然就能知道它往哪个方向跑了、跑得有多快,就像你盯着一个在操场上跑步的人,拍两张照片就能算出他的速度和轨迹一样。
不过如果视频有几十帧,每一帧都去算这么一套东西,计算量还是太夸张,所以V-DPM又做了一些聪明的减法。它把所有视角都统一到第一帧的相机角度上,这样就不用反复处理不同视角带来的麻烦,然后它只挑两套关键的东西去预测。
一套是每张图在自己那个时刻的三维样子,另一套是所有图在某个固定参考时间点的三维样子,有了这两套东西,就能把整个动态过程串起来,而且计算量一下子就降下来了。
模型结构这块,VGGT原本的骨架是被完整保留下来的,因为它已经在大规模静态数据上练就了火眼金睛,能很准确地理解场景的三维结构,没必要把这些本事扔了。
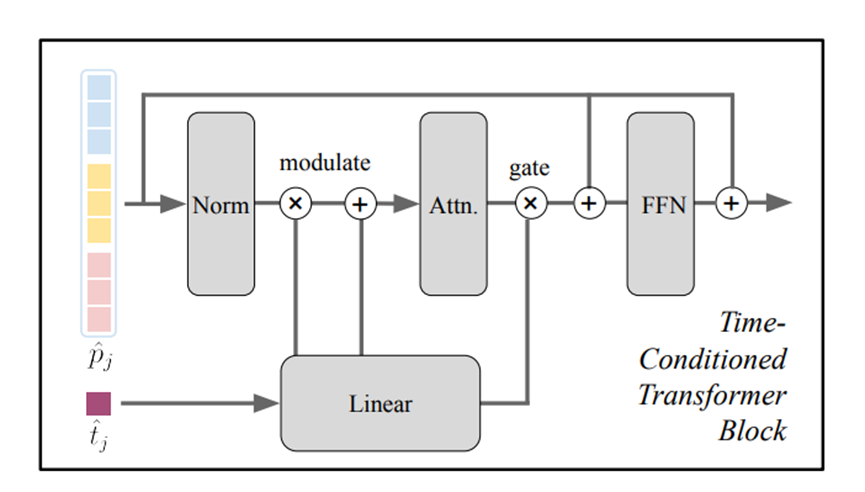
团队主要是在解码阶段动了脑筋,加了一个专门处理时间信息的模块。这个模块有点像个翻译官,它能把不同时间帧的特征信息对齐起来,然后根据你指定的某个时间点,把那个时刻的完整三维场景给翻译出来。
为了让这个翻译官干活更利索,他们还用了自适应层归一化的技术,说白了就是根据时间信息来调节模型内部神经元的反应强度,这样模型就能精准地知道现在要处理的是哪个时刻的画面。

整个训练过程也挺讲究,因为动态场景的标注数据少得可怜,要想从零训练一个模型既费钱又费时。
V-DPM采取了混搭的策略,拿大量的静态数据打底,再辅以一些动态数据微调,就像教一个人先学素描,再让他学画动画,基本功打好了,动态的东西学起来也快。
登录/注册后继续阅读
立即登录/注册 >































