
我要认证
2026-01-21
Meta超级智能实验室和伊利诺伊大学的研究人员联合开源了一个重磅AI智能体模型Dr.Zero。
Dr.Zero可以让搜索智能体在完全没有训练数据的情况下实现了自主进化,而且性能一点不输给那些靠大量人工标注数据训练的模型,甚至在不少复杂问答测试里还反超了,最高能提升14.1%的性能。
直接打破了AI训练对人工数据的依赖,以后在没什么数据的场景里也能轻松搞智能体开发了。

开源地址:https://github.com/facebookresearch/drzero
论文地址:https://arxiv.org/pdf/2601.07055
现在搞AI最头疼的就是数据问题。高质量的数据越来越难搞,要么得花大价钱请人标注,要么就是根本找不到合适的。
传统的搜索智能体训练更是离不开人工整理的问题集、上下文或者标准答案,不仅费钱费力,面对开放域里那些复杂的推理需求,还经常力不从心。
虽然之前也有自进化的智能体,能自己提问题、找答案、学经验,但大多只适用于数学这种特定领域。
在这些领域里,问题定义得比较窄,就算数据多样性不够,也能有点提升。可一到开放域问答就歇菜了,要么还是得靠人工设计问题,要么就得要大量上下文和标注,根本算不上真正的自主进化。
还有个计算效率的坑。以前用的GRPO算法,训练的时候得搞嵌套采样,一个问题要生成好几个查询,每个查询又要多个响应,计算量直接爆炸。
再加上多轮推理的高延迟,想用来训练需要复杂工具交互的自进化代理,基本不现实。
而Dr.Zero主要靠三个核心设计,彻底解决了之前的难题。整个框架就靠外部搜索引擎当知识来源,一开始用同一个基础大模型,分别造出提议者和求解器,然后让它们俩互相促进内卷,一起进步。
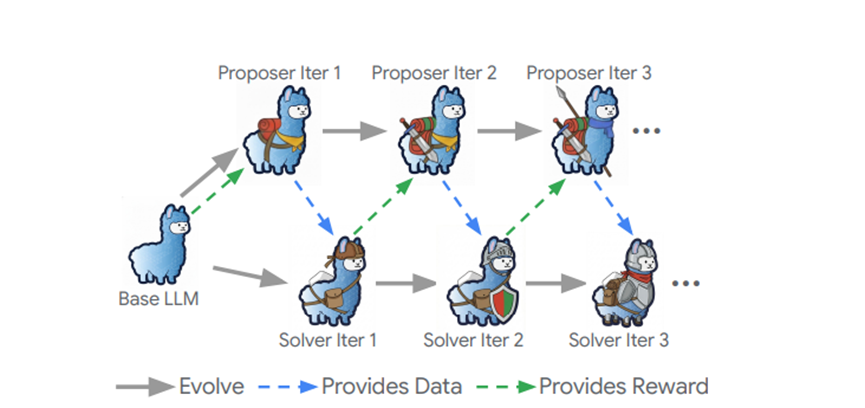
提议者和求解器:这是整个框架的核心,就像一个老师和一个学生,只不过老师和学生是同一个起点,还能一起成长。
提议者的活是生成各种有挑战性还能验证的问答对,它不像传统模型那样只会造简单问题,而是有个多轮工具使用的流程,能生成复杂的多跳问题。
求解器就负责解决提议者出的题,一边做题一边提升自己的搜索和推理能力。它也能调用搜索引擎,思考的时候先在心里过一遍逻辑,要是发现自己不懂,就精准搜一下,补全知识缺口,直到能给出明确答案。
它的目标就是把题做对,随着提议者出的题越来越难,求解器也得不断优化自己的搜索和推理方法,不然就跟不上了。
它们俩的优化是交替进行的:提议者先出一批题,求解器做完之后,把结果反馈给提议者,提议者根据反馈优化自己的出题思路;而提议者出的这些高质量题目,又成了求解器的训练素材,让求解器继续提升。
为了解决之前GRPO算法计算量大的问题,Dr.Zero搞了个HRPO算法,也就是跳数分组相对策略优化。简单说就是把结构相似的问题归为一类,一起计算,不用再一个个单独处理,大大降低了计算成本。
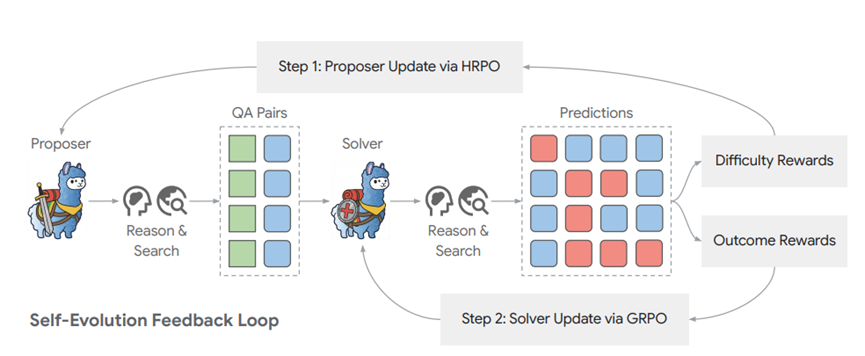
这里的跳数就是推理链的节点数,单跳问题就像小学应用题,一步就能算出答案;多跳问题就像复杂的综合题,得好几步推理加搜索才能解决。
HRPO把相同跳数的问题分到一组,然后在组内对求解器的奖励分数进行标准化,这样就能算出更稳定的优势估计,不用再搞嵌套采样。
为了让提议者别出太简单或太离谱的题,Dr.Zero设计了一个难度引导的奖励机制。核心就是看求解器的答题通过率:要是求解器全做对了,说明题太简单,提议者拿不到多少奖励;要是全做错了,说明题太难,也没奖励。
只有当求解器部分做对、部分做错,说明题难度适中、有挑战性,提议者才能拿到高分。
这样一来,提议者就会主动去出那些刚好在求解器能力边缘的题,既保证能验证答案,又能推着求解器不断进步。
再加上之前说的格式奖励,就能确保提议者生成的题不仅有挑战性,格式还规范,求解器能顺利解析,不会因为格式问题卡壳。
为了测试Dr.Zero的性能,研究人员使用了Qwen2.5-3B和7B两个版本进行测试,不管哪个版本,Dr.Zero的表现都很能打。
登录/注册后继续阅读
立即登录/注册 >































