
我要认证
2026-01-20
现在实体AI机器人赛道很火,但有个问题一直没解决好,就是怎么能让机器人精准get到“运动”这件事。不管是让机器人干精细活,还是用文字生成连贯的视频,都得先搞懂接下来该怎么动。
之前那些模型不是只能抓个大概,就是得靠一大堆精准标注的数据,普通场景根本用不转。
全球第一CRM公司Salesforce的AI团队搞了个创新模型FOFPred,把视觉语言模型和扩散架构凑到一起,居然可以用语言直接指挥未来的运动轨迹,机器人操控和视频生成一下就有了质的飞跃。

论文地址:https://arxiv.org/pdf/2601.10781
Github:https://github.com/SalesforceAIResearch/FOFPred
你想想,让机器人帮你递个东西,它得知道手该往哪动、动多快,总不能只看眼前的画面和你的指令就瞎猜吧?以前的机器人模型就是这么干的,只靠RGB图像和文字,经常“理解跑偏”,复杂点的任务根本扛不住。
还有视频生成,你说“让蝴蝶从左飞到右”,以前的模型要么飞得歪歪扭扭,要么干脆没动静,就是因为没搞懂运动的本质。
光流其实是个好东西,它能捕捉每个像素的运动轨迹,就像给画面里所有东西都画了运动路线图,比那些只标几个点的稀疏轨迹靠谱多了。

但难就难在,怎么让机器预测未来的光流,还得听语言的指挥。而且网上那些人类活动的视频虽然多,但又吵又乱,字幕也不准,根本没法直接用。
而FOFPred直接解决了这个大难题,算是把VLM和扩散模型玩明白了,把它俩捏在了一起。
模型要干活,得先知道“看什么”和“听什么”。它会同时接收两张连续的画面和一段文字指令,比如“把瓶子从左边移到右边”。
FOFPred先靠Qwen2.5-VL这个视觉语言模型,把文字和画面揉在一起,提取出两者的关联特征。
比如“瓶子”和“左边到右边”的对应关系。再用Flux.1VAE把画面单独编码,变成机器能读懂的视觉特征,还会把文字和视觉特征调成一样的格式,方便后续处理。
另外,还会加一点随机噪声,让模型能生成更多样的运动方式,不会死板一块。
扩散Transformer是FOFPred的核心,相当于整个系统的决策中心。基于OmniGen2DiT做了改进,专门针对“时间序列”做了优化。
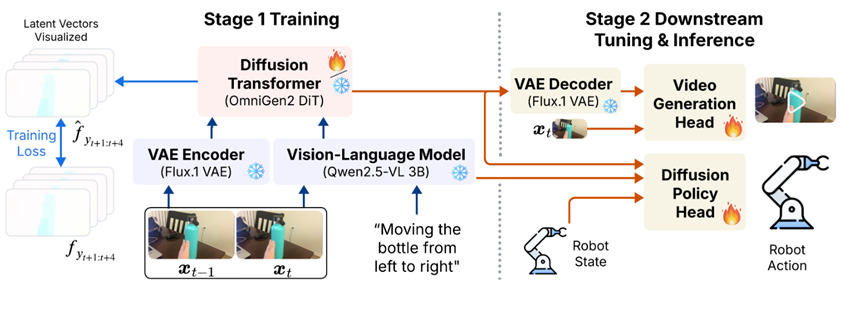
就像我们看视频能记住前一秒的画面,这个模块能给每帧画面打上“时间戳”,清楚区分哪帧是过去、哪帧是未来。
再加上时空注意力机制,能同时关注画面里的空间位置和时间变化,比如瓶子现在在哪、接下来该往哪动,都能算得明明白白。而且这个模块只训练关键部分,其他权重都保持不变,既保证了效果又省了不少算力。
以前的光流都是一堆复杂的向量,机器处理起来费劲,还没法利用现成的强大模型。FOFPred想出了个绝招,把光流转换成RGB图像的形式。它先把光流的运动幅度和方向,转换成极坐标,再映射到HSV颜色空间里。

不同的运动方向对应不同的颜色,运动快慢对应颜色深浅。这样一来,光流就变成了一张彩色的“运动地图”,既能被VAE这样的模型高效处理,还能直观看到运动轨迹,简直一举两得。
登录/注册后继续阅读
立即登录/注册 >































