
我要认证
2026-01-13
现在的大模型卷参数已经卷到千亿甚至万亿级别,但总感觉有点用力过猛。比如让超级计算机去查字典,明明一眼能找到的答案,非要绕着圈子计算半天。
而今天凌晨,DeepSeek、北大的研究团队直接搞出了Engram架构,算力需求大降,把大模型的稀疏性玩出了新花样。

咱们先说说以前的大模型为啥效率低。语言这东西本来就分两种活,一种是需要动脑子的推理,比如解数学题、分析文章逻辑;
另一种就是简单的知识回忆,比如知道“四大发明”是啥、“戴安娜王妃”是谁。
但传统Transformer架构不管这些,全靠计算搞定。就拿识别“戴安娜王妃”来说,模型得用6层网络一步步拼凑,前3层只知道“威尔士”是个地方,到第6层才认出完整实体。
这就像让你做数学题时,先花半小时默写乘法口诀,纯粹浪费时间。宝贵的网络层被用来干“查字典”的活儿,真正该用在推理上的资源就少了,难怪很多大模型知识问答还行,复杂推理就拉胯。
而Engram的核心思路就是要把计算和记忆给彻底分开。简单来说,就是给大模型外挂了一个超级百科全书,专门用来存那些固定的知识,像是什么历史年份、名人名字、代码里的固定语法这些。
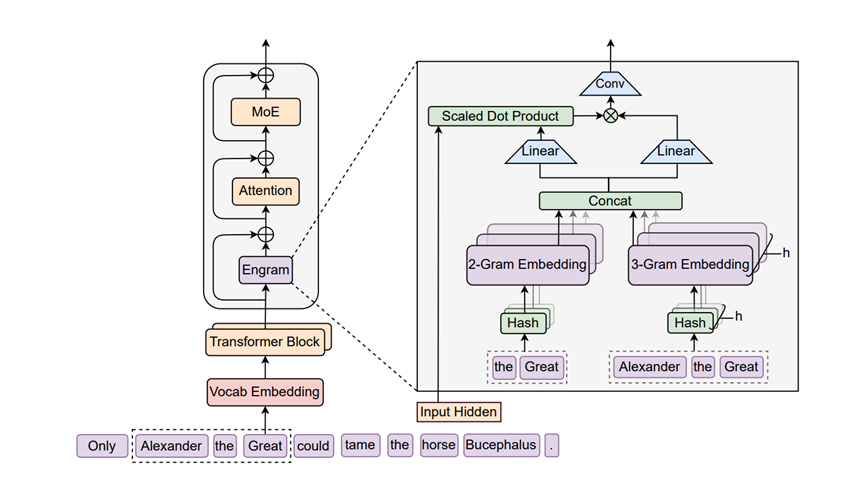
Engram就像是给大脑配了个直接索引,想查什么直接伸手去拿,完全不耽误脑子去干更复杂的逻辑推理活。
咱们深入一点看Engram的核心技术,它到底是怎么做到的。首先啊,这玩意得解决一个特别现实的问题,就是咱们平时说话用的词儿太碎了。
比如Apple和apple,意思其实差不多,但计算机非得把它当成两个完全不同的东西来存。
Engram就很聪明地做了一步压缩,把大小写、格式不一样但其实是一个意思的词全都归为一类,这么一整理,词汇表一下子就精简了不少,存起来自然就快多了。
紧接着又来了个挺有意思的操作,叫多头哈希。大家可能觉得存N-gram这种连续的词组,比如Artificialintelligence,组合起来是个天文数字,根本存不下对吧。
这帮人想了个招,用类似抽奖摇号的方式,通过一个算法把长长的词组映射到一个固定的格子里去,哪怕偶尔几个不同的词撞车了也没事,后面还有办法修补。
这样就能在有限的空间里塞进海量的词组模式,而且查找速度特别快,哪怕你有一万个词要查,它也能在一瞬间找到。
光找到还不行,因为这毕竟是死记硬背的东西,万一跟上下文冲突了怎么办。比如我刚才说Java,你不知道我说的是咖啡还是编程语言。
Engram这里设计了个特别灵巧的门控机制,它就像个特别懂眼的管家,先看看现在的语境,如果发现从记忆里拿出来的东西跟现在聊的天不搭界,它就自动把音量关小,甚至直接忽略。
如果发现特别对口,它就把这个记忆大声告诉模型。这种动静自如的感觉,真的是把大模型调教得像个活人一样。
而且为了不让这个外挂记忆显得太呆板,他们还加了一点深度卷积在里面。这就好比给那些死板的记忆加了一层滤镜,让它们能更好地融入到当前的句子里去,不至于显得格格不入。通过这一套组合拳下来,Engram不仅记得多,还记得灵活。
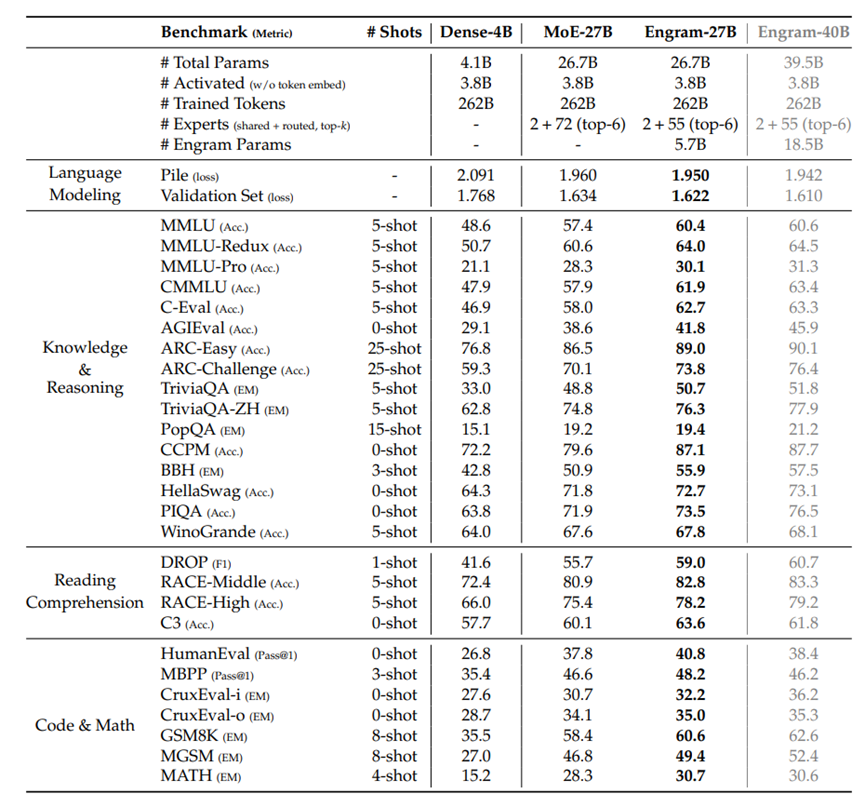
为了评估Engram的性能,研究团队训练了四个模型对比,41亿参数的稠密模型、267亿参数的MoE模型、267亿参数的Engram模型,还有395亿参数的超大Engram模型。
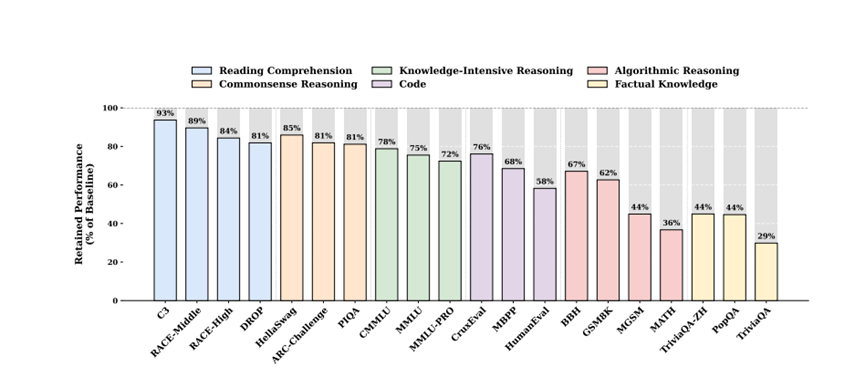
测试结果显示,Engram架构模型直接断层领先。
知识类任务不用多说,MMLU准确率比MoE高3%,中文的CMMLU高4%,零样本的AGIEval更是领先3.2%,相当于知识点记得更牢更准。
让人意外的是推理类任务,提升更明显。BBH逻辑推理高5%,ARC-Challenge高3.7%,阅读理解DROP高3.3%。原来把“查字典”的时间省下来,模型真的能更专注于推理,就像学生不用死记硬背公式,能把更多精力放在解题思路上。
登录/注册后继续阅读
立即登录/注册 >































