
我要认证
2026-01-12
现在数字孪生、机器人这些技术发展得越来越快,大家对4D场景的需求也越来越多。所谓4D就是3D加上时间维度,简单来说,就是要让虚拟世界里的物体像现实中一样会动、会变形、还能互相作用。
但之前想做个像样的4D场景太难了,要么得靠专家一点点手动建模,费时间还不灵活;要么得有海量的4D数据集,可这种数据本来就少,还大多只覆盖单个物体,想做多个物体互动的场景根本不现实。
斯坦福、剑桥和马里兰大学的研究人员联合开发了创新模型CHORD来解决这个大难题,一张图片+一句话就能生成逼真4D动画。

例如,一个孩子用跷跷板发射一块砖头
刺客信条主角艾吉奥和他的老鹰在玩耍
一只海狮在玩沙滩球
CHORD这个名字取得也挺有意思,全称叫Choreographing Dynamic objectsand scenes,听起来就像是在给这些物体编排舞蹈,而它找来的那个“总导演”,竟然是现在火得不行的2D视频生成模型。
这帮人有个特别聪明的洞察。现在的视频生成模型,像Wan2.2这种,在互联网上看了那么多视频,其实潜意识里已经懂了这个世界是怎么运转的,知道东西掉了会往下掉,碰到软的东西会凹陷。
那与其费劲去收集稀缺的4D数据训练模型,不如直接把这些视频模型当作一个严厉的老师。
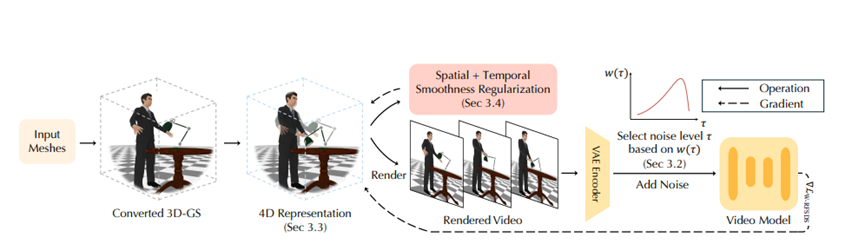
咱们手里有个静态的3D场景,就试着去调整它的形状和位置,然后渲染出来给视频模型看。
视频模型就会告诉我们,不对,根据我的经验,这会儿这个位置应该是这样的。咱们就根据它的反馈不断修改,最后修出来的样子,就是一段逼真的4D动画。
不过话说回来,光有这个想法落地难度简直地狱级。4D形变这事儿涉及的时间和空间维度太高了,要是硬算,计算机非得冒烟不可。
而且现在的视频模型大多用的是整流流架构,跟以前咱们熟悉的扩散模型不太一样,直接套用老办法根本行不通。CHORD团队为了搞定这两个拦路虎,那是下了真功夫,整整搞出了三个大杀器。
首先得解决怎么表示运动这个问题。咱们总不能把每一帧每一个点的位置都存下来吧,那数据量太大了,而且容易乱。他们搞了个分层的办法,就像咱们画画先勾大轮廓再填细节一样。
在空间上,用一套稀疏的控制点管大动作,比如胳膊抬起来这种,然后再用密集的控制点管细节,比如手指怎么扣。优化的时候也是先练大动作,等动作顺了再扣细节,特别符合人类直觉。
更有意思的是他们在时间维度上玩了个花活,借用了计算机科学里叫芬威克树的数据结构。
以前做动画很容易出现这一帧和下一帧脱节的情况,动作抖得像帕金森。这帮人把时间上的形变变成了一种累积的结构,这一帧的动作是基于前几帧累加出来的。
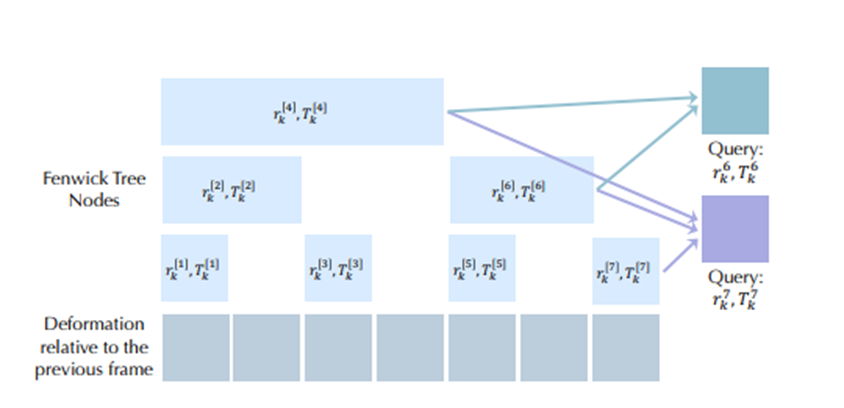
这么一来,前后帧自然而然就有了极强的关联,想不连贯都难,从根上杜绝了动作突然抽搐的毛病。
有了好的表示方法,还得让视频模型愿意教。针对整流流模型这个特殊的“老师”,他们专门推导了一套新的学习规则。
这就像是你要驯服一匹烈马,得用特定的套路。而且他们发现一个特别实用的小窍门,就是在学习初期故意加很多噪声,让模型看不清细节,只能关注大轮廓的运动,这样模型就会专注于把大动作改对。
等到动作骨架搭好了,再慢慢降低噪声,去磨那些像素级的细节。
要是反着来,一开始就纠结细节,最后生成的动作往往看着特别别扭,甚至东西会飘在空中不落地。
登录/注册后继续阅读
立即登录/注册 >































