
我要认证
2026-01-11
大家最近有没有觉得,现在的AI视频生成虽然越来越像真的,但总感觉少点什么?明明画面挺精美,可你想让它镜头往左挪一点,或者让路边的车跑个特定的路线,它就开始抽风了,不是物体穿模就是背景扭曲。
这就像是你指挥一个乐队,只能告诉大家大概要个什么氛围,至于具体哪个音符在什么时候响,完全看运气。
所以,复旦大学、上海创新研究院、香港大学和腾讯ARC实验室的研究人员联合开源了一个创新框架VerseCrafter算是把这个难题给解决了。
它的核心思路特别简单,既然是视频世界,直接用真正的4D思维来管它,而不是在平面上瞎猜。

咱们先聊聊为啥以前的方法那么笨。大家拍视频都知道,现实世界是三维的空间加上一维的时间,是个立体的过程。
但AI以前看视频,本质上还是把这一帧帧画面当成平面的图片来处理。它学到的是像素怎么变,而不是物体在空间里怎么动。
这就会导致一个很尴尬的局面,你想让镜头转个圈,它可能只会把画面旋转一下,物体跟着一起转,完全不符合物理规律。
后来也有人想引入3D信息,但大多是把摄像机控制和物体控制分开搞。要么只管镜头不管物体,要么管物体还得靠那种死板的方框框住。
只要镜头一动,那个方框里的东西要么飘了,要么变了,根本没法在复杂的场景里同时管好镜头和好几个乱动的家伙。
VerseCrafter这次最聪明的地方,就是搞了一套全新的“4D几何控制”表示法。这听着挺玄乎,其实理解起来不难。
它把整个视频世界拆成了两部分,一部分是静止的舞台,另一部分是上面跑龙套的演员,然后把它俩都放在同一个世界坐标系里。
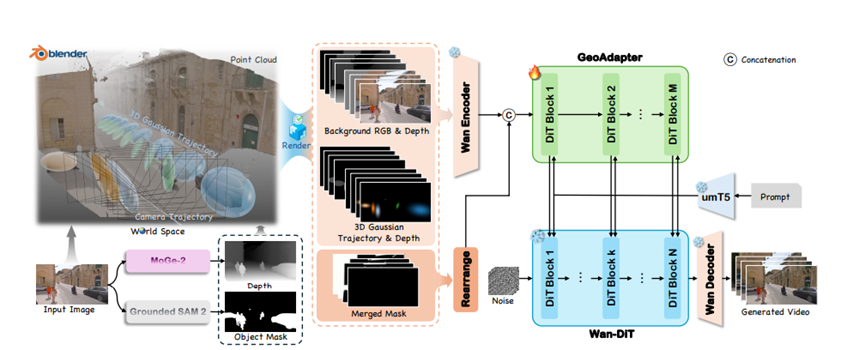
对于静止的背景,比如房子、树、马路,系统会根据一张图,利用单目深度估计算法估算出深浅,再把像素反投回3D空间变成一堆点。
这就像是给场景搭了个钢筋骨架,不管你怎么转镜头,这个骨架是不动的,渲染出来的背景自然就特别稳,不会出现墙歪了窗户飞了的奇怪bug。
那有人会问,怎么处理那些动来动去的物体,像人啊车啊之类的呢?以前的方法爱用那种硬邦邦的3D方框去套物体,但这玩意儿太死板,遇到个姿势扭曲的人或者形状怪异的车就抓瞎了。
VerseCrafter用了3D高斯分布来解决。咱们可以把它想象成一个有弹性的棉花糖或者橄榄球。这个棉花糖中心在哪儿代表物体位置,它的形状是扁是圆代表物体朝向和大小。把这一串棉花糖按时间连起来,就是一条轨迹。
这种表示法特别通用,不管你是人还是猫,甚至是个奇形怪状的飞船,都能用这套语言描述。
而且对咱们创作者特别友好,可在Blender这种3D软件里,就像捏橡皮泥一样,拖动这些棉花糖的位置和形状,AI就能明白你想让这物体怎么动。
有了这么好的控制思路,接下来就是怎么让AI听懂。这里不得不提一下他们那个“站在巨人肩膀上”的机智做法。
他们没有从头训练一个巨大的视频模型,而是直接用了那个性能很强的Wan2.1-14B模型作为底座,让它保持原样不动。
然后,他们专门设计了一个叫GeoAdapter的小插件。这个插件的作用就是把前面那些3D背景和棉花糖轨迹转换成AI能看懂的信号。
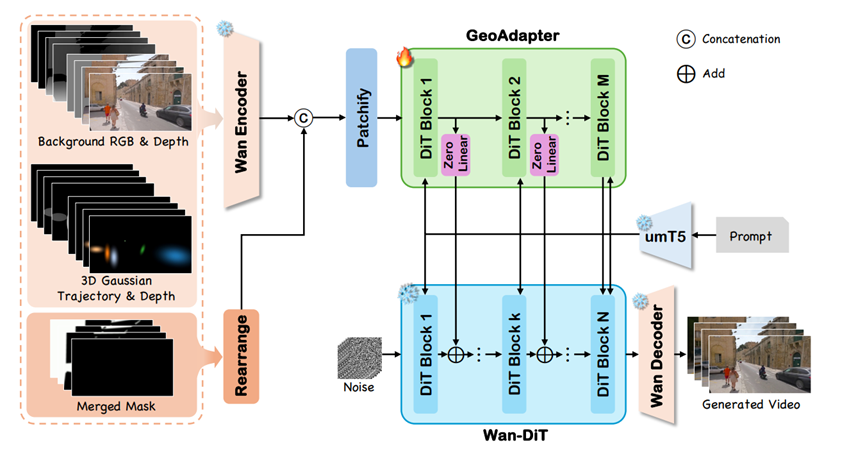
它会把3D状态渲染成一张张包含了颜色、深度的控制图,然后塞给这个GeoAdapter。这个小插件会把4D几何信息提取出来,像加盐一样撒进主模型的大脑里。这样一来,大模型原本强大的生成画面的能力保留了下来,同时又多了双听从几何指令的耳朵,既听话又能干。
不过光有聪明算法还不行,得有数据喂。你想让AI学会精准控制,总得给它看大量带着标准答案的视频吧。
但这事人工标注根本不可能,谁有空去给视频里每一帧的每一个物体画3D轨迹啊。于是团队搞了一套全自动的数据引擎,造出了VerseCrafter 4D数据集。这流程真是有点全自动流水线那味儿了。
登录/注册后继续阅读
立即登录/注册 >































