
我要认证
2026-01-11
多模态大模型早就能处理音频和视频了,像Qwen3-Omni、Gemini2.5-Flash这些模型看着挺厉害,但用起来才发现问题不少。要么是没法精准捕捉细节,要么是音频和视频对不上号,实际用起来总掉链子。
为了解决这些难题,浙江大学、西湖大学和蚂蚁集团联合搞出了OmniAgent框架。
这玩意完全不按传统套路来,靠音频当向导主动找关键信息,在三大权威测试里都拿了第一,给多模态理解指了条新路子。

之前那些端到端的多模态模型,看着是把音频和视频整合到一起了,但实际用起来全是槽点。首先是对齐难,就像让说方言的和说普通话的人硬聊,俩模态的信息根本对不上。
比如Qwen-Omni处理视频时,为了适配模型只能压缩画面,导致音频里的细节和视频里的内容脱节。
然后是抓不住重点,这些模型就像只会看全景图的人,没法聚焦到具体的文字、小事件上,处理带特定信息的音视频时经常出错。
还有就是效率低,要么按固定流程走死路,要么靠逐帧加字幕,又费资源又容易受干扰,想兼顾精准度和速度简直难如登天。
西湖大学的王欢教授团队发现,单看音频或视频模型都挺能打,但凑到一起就拉胯,核心问题就是时间对不上、特征不匹配。
蚂蚁集团的算法专家刘健说得更直白,现有系统就是被动接收信息的冤大头,不管有用没用全收下,不仅浪费算力,关键信息还被一堆没用的数据盖住了。
也正因为这些坑,团队才想搞个能主动找线索的模型,就像侦探查案一样,精准定位关键信息。
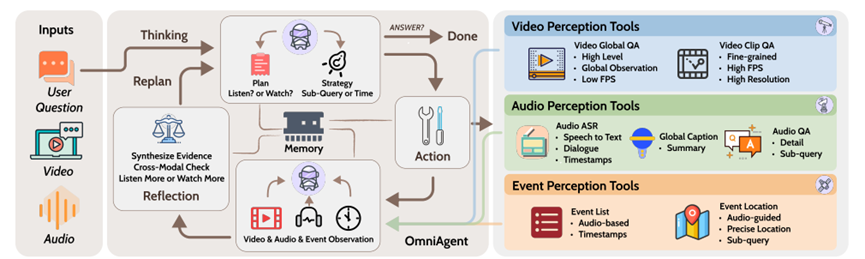
OmniAgent最强的地方,就是把多模态理解从被动接收变成了主动探究。它以大语言模型为大脑,自己决定该听什么、该看什么、什么时候调用工具,完全不用人催。
为了实现主动探究,团队给OmniAgent配了三套专属工具:视频工具分两种,一种管全局一种抓细节。全局工具用稀疏采样的方式,快速判断视频里有没有目标,比如先扫一眼就知道视频里有没有小猫;
细节工具就厉害多了,能在关键时间段里提高帧率和分辨率,仔细分析物体的样子、位置这些细节,就像用放大镜看重点区域一样。而且它特别省资源,只在关键片段发力,视觉输入令牌从传统的18.6k降到了8.3k,准确率还提升了不少。
音频工具更是核心,能做三件事。一是把语音转成带时间戳的文字,比如博主说的话能精准对应到具体时间;二是总结音频环境,快速判断是对话、音乐还是环境音;三是针对性查音频细节,比如专门找有没有猫叫声。
音频信号处理起来又快又省资源,比处理视频像素数据轻松多了,光靠音频筛选就能把后续要分析的视频范围缩小60%以上,效率直接拉满。
事件工具是找线索的关键,一套负责提取音频里所有能检测到的事件,建立全局认知;另一套能根据需求精准定位事件发生的时间,比如听到猫叫就立刻锁定这个时间段,给视频分析定好锚点。
这玩意彻底不用逐帧扫视频了,靠音频线索找关键时间,准确率高达80.67%,还能省45%的计算成本,长视频里找关键事件再也不用大海捞针了。
OmniAgent的工作流程特别有意思,就像侦探查案,一步一步逼近真相。首先是主动思考,拿到用户需求后,根据已有信息决定先听还是先看,比如要找视频里的文字标识,就先靠音频找线索。
然后是行动观察,调用对应的工具收集信息,不管是文字、时间戳还是高清画面,都存到记忆里。
最后是反思重规划,看看收集到的信息够不够、有没有矛盾,比如音频听到了南柯两个字,视频里没找到,就再调用高清视频工具仔细找,直到证据足够给出答案。
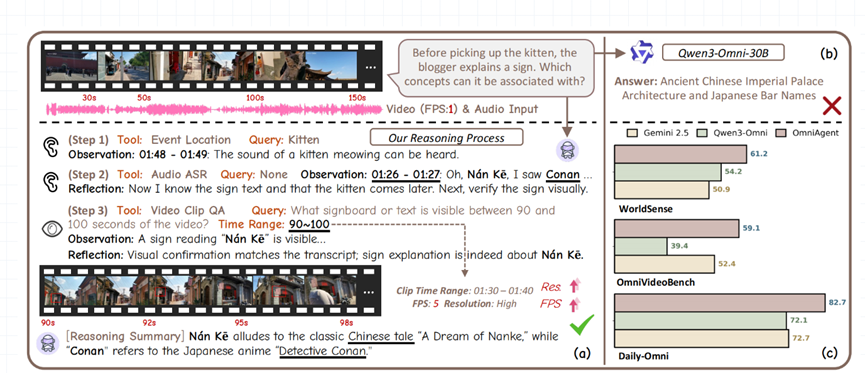
之前有个测试案例特别能说明问题,要找视频里悬挂标识的两个汉字关联的概念。OmniAgent先靠猫叫声锁定关键时段,再通过音频转文字拿到南柯线索,最后在视频里验证,准确关联到中国古典寓言和日本动漫,而传统的Qwen3-Omni-30B直接答成了古代宫殿和日本酒吧,差得不是一星半点。
OmniAgent解决模态对齐的办法很聪明,靠音频当向导分三步来。第一步先靠音频快速扫全局,找到可能有关键信息的时间段;
第二步在这个时间段里,让音频和视频互相验证,比如音频转的文字和视频里的字幕对一对,精准锁定目标;第三步再用高清视频工具仔细分析细节,结合音频语义得出最终答案。
这套流程下来,音频和视频再也不会对不上号了,跨模态对齐准确率提升了30%以上,之前的老大难问题直接解决。
为了检验OmniAgent的实力,团队在三个权威测试里和16款主流模型正面刚,不管是短视频、长视频还是多领域场景,表现都一骑绝尘。
测试设置特别严谨,OmniAgent用OpenAIo3当大脑,最多推理30步,视频靠Qwen3-VL,音频和事件定位用Gemini-2.5-Flash,还特意关掉了工具自带的推理功能,确保成绩是框架本身的实力。
登录/注册后继续阅读
立即登录/注册 >































