
我要认证
2026-01-08
多模态AI大模型一直是个研究难点,语言模型写文案、做推理是一把好手,但让它生成或编辑图片就抓瞎;扩散模型能出高质量图片,可你让它理解复杂指令、做逻辑推理又完全不行。
而字节跳动联合清华、莫纳什大学的研究人员重磅开源了NextFlow,一个模型就能搞定理解、生成、编辑所有事,1024×1024的高清图5秒就能生成。
比之前那些自回归模型快了不止一点半点,同时算力还暴降了6倍左右。

其实行业里一直在尝试多模态,主要分两派。一派是搞混合架构,把自回归和扩散模型凑一起,看着能兼顾两边的优点,但实际用起来会有额外的计算开销。就像用两台不同系统的电脑协作,文件来回传特别麻烦。
另一派是纯自回归模型,想靠一个架构包打天下,可问题更明显。之前的纯自回归模型生成图片,都是像扫二维码一样逐点生成,分辨率越高,生成时间就成倍增加。
一张1024×1024的图要等10多分钟,完全没法实际用。而且它们对图片的理解也很浅,只能捕捉到像素层面的信息,没法get到高层的语义,比如你让它“把夏天的枫叶改成绿色”,它可能都理解不了夏天枫叶该是什么状态。

NextFlow模型最大变革就是,看透了文本和图片的本质区别。文本是一句一句按顺序来的,但图片是有层级的,先有大致轮廓,再有细节。抓住这个关键点,它就彻底解决了之前的那些痛点。
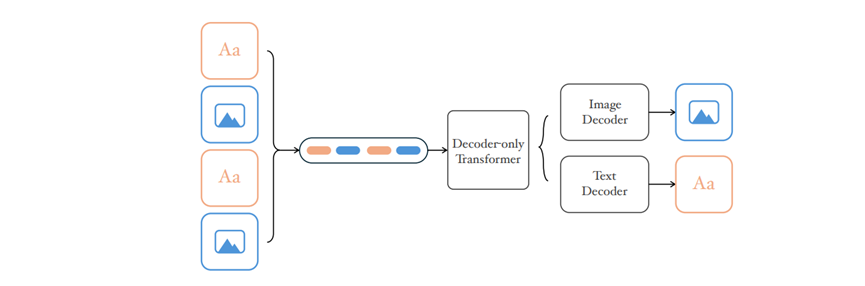
NextFlow的核心思路就是“统一”,用一个模型搞定所有事。双码本Tokenizer让模型既懂语义又懂像素。就像我们看一张图,既要知道里面画的是什么,也要看清细节好不好。
NextFlow的双码本设计就是干这个的,一个码本专门负责捕捉图片的核心概念,比如这是一只猫、在草地上;另一个码本负责还原细节,比如猫的毛发纹理、草地的颜色深浅。
这俩码本还能互相配合,不会顾此失彼。而且它还支持不同分辨率和宽高比的图片,不用强行把图片拉伸或裁剪成固定尺寸,生成的图片自然更协调。对比之前那些单一码本的模型,它生成的图片不仅像,还更懂你想表达的意思。
Next-scale预测,生成图片像搭积木一样高效。之前的模型生成图片是逐点扫描,就像用针一点点绣一幅画,慢得要死。
NextFlow改成了分层生成,先搭个大致框架,再慢慢补细节,就像盖房子先打地基、搭骨架,再装修内饰。
比如生成一张1024×1024的图,它先生成2×2的粗略轮廓,再扩展到4×4、8×8,一步步把细节补全。这样一来,计算量大大减少,速度自然就上去了,5秒搞定高清图就是这么来的。

为了让模型能分清不同层级的重要性,它还会给早期的粗框架更高的权重,避免出现“细节很精致但整体布局乱七八糟”的情况。
而且它还能自我纠错,前面步骤生成得不够好,后面能及时调整,减少图片里的奇怪伪影。
NextFlow的解码器特别简洁,就一个输出头,既能处理文本又能处理图片,不像有些模型搞一堆专用头,复杂还容易出问题。它还加了一些小优化,让模型能更好地适应不同尺寸的图片,生成的一致性更高。
不过离散编码难免会损失一些高频细节,比如小尺寸的文字、人脸细节。所以它还加了个可选的扩散解码器,就像给图片做后期精修,需要超写实效果的时候打开就行。
但这个功能也有取舍,精修的时候可能会轻微改变一些细节,所以日常使用默认关闭,按需启用就好。
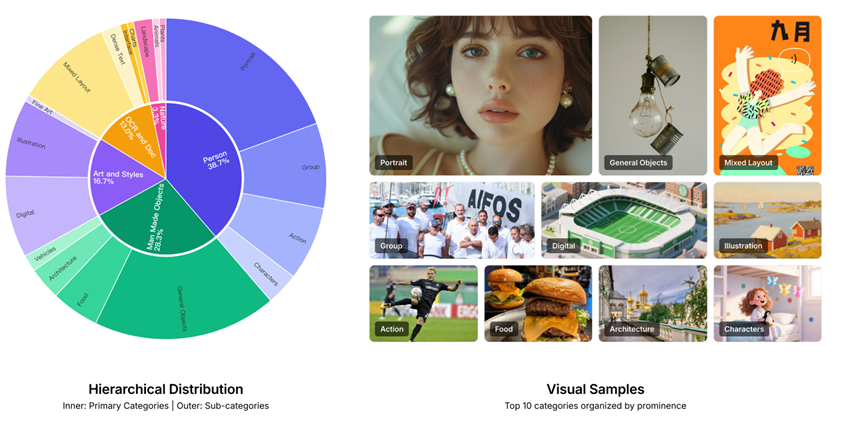
模型再聪明,没有好数据也白搭。NextFlow的训练数据规模是真的大,足足6万亿个文本和图像的离散token,涵盖了各种场景。
它的训练过程也很有讲究,不是一下子就上高分辨率,而是从256分辨率开始,慢慢升到512、1024,让模型循序渐进地学习。
登录/注册后继续阅读
立即登录/注册 >































