
我要认证
2026-01-05
现在的智能体是越来越强,不管是电脑上的办公自动化,还是手机上的各种日常操作都能轻松完成。
但说真的,这些智能体做完任务后怎么确认它真的做好了,是个大难题。之前要么得靠人写一堆复杂的规则脚本,要么就得让验证工具从头到尾翻看智能体的所有操作记录,又费时间又费钱,还经常出错。
腾讯优图实验室直接开源了SmartSnap把这一大难题给突破了。这是一个能自我证明的智能体,不仅能完成任务,还会主动搜集关键证据,不用再麻烦外部工具做复杂验证。

在SmartSnap出来之前,智能体验证真的能把人逼疯。你想啊,智能体在手机上完成个任务,比如记录一笔expenses或者开个深色模式,要确认它真的做好了,以前就两种办法。
一种是给每个任务写专属的验证脚本,相当于给每个任务量身定做一把钥匙。但手机应用那么多,任务五花八门,光写这些脚本就得花大量时间,根本没法大规模用。
像AndroidLab这个测试平台,光9个应用就有138个任务,逐个写脚本根本不现实。
另一种更常见的,是让验证工具把智能体的所有操作轨迹都看一遍。这就好比老师批改作业时,不光看答案,还得把学生的草稿纸、演算过程甚至涂改的地方都从头到尾研究一遍,工作量大到惊人。
而且这些操作记录里好多都是没用的冗余信息,验证工具看着看着就容易走神,出现判断失误,比如明明没做好,却误判成完成了。
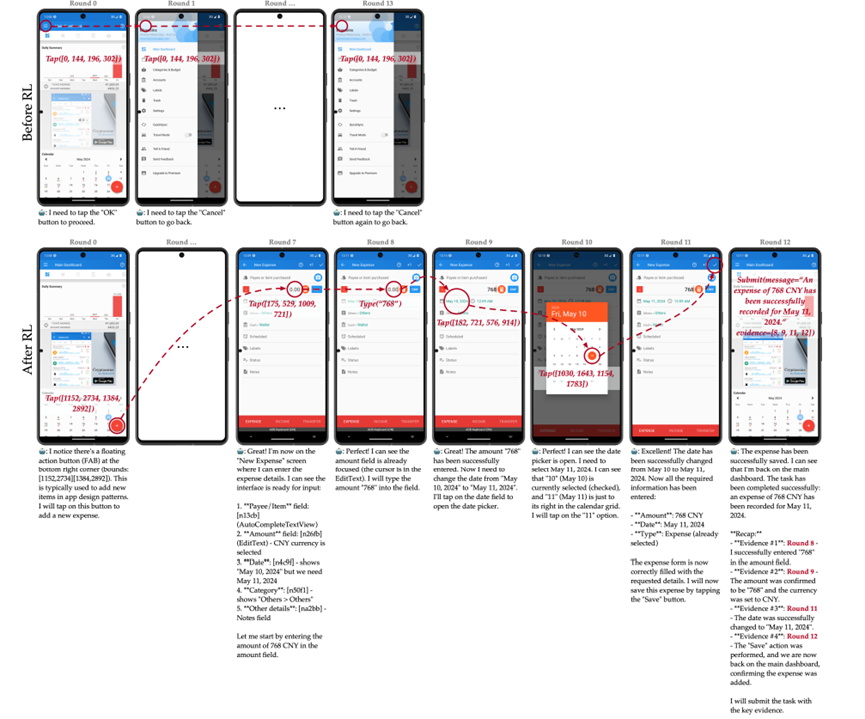
更关键的是,以前的智能体根本没有自证的意识。它就像个只管干活不管汇报的员工,做完任务就等着领导检查,自己不会主动整理工作成果。
这样一来,训练的时候也没法形成对任务的深层理解,只能机械模仿别人的操作,换个类似任务就容易掉链子。
现在SmartSnap要求智能体身兼两职:既要把活干好,还要主动搜集证据证明自己干好了。
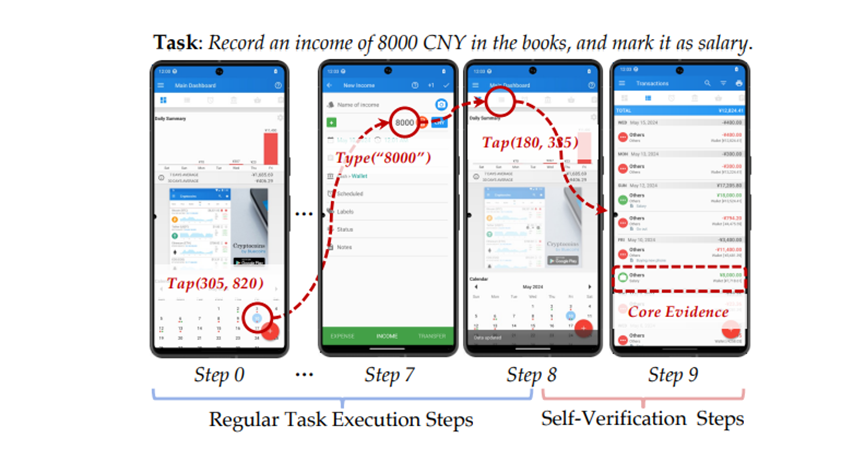
比如安装浏览器插件这个任务,以前的智能体点击“添加扩展”按钮,看到对话框消失就觉得任务完成了。
但SmartSnap训练出来的智能体,点击之后还会主动去检查浏览器工具栏,看看新插件的图标是不是真的出现了。这个额外的检查动作,就是在搜集最关键的证据,确保任务真的完成,而不是表面上看着完成了。
这种主动找证据的行为,还能让智能体更懂任务本质。它得想清楚,到底什么证据能真正证明任务完成,而不是随便凑数,这就比机械执行动作高明多了。
为了让智能体知道该怎么搜集证据,腾讯优图团队总结了三个原则,简称3C。这三个原则就像给智能体定了搜集证据的规矩,确保证据又全又精又管用。
完整性原则:关键的操作证据不能少。比如填写表格的任务,每个必填字段的填写过程都得有证据,不能漏掉重要步骤。不然验证工具看不到关键环节,可能会误判任务没完成。
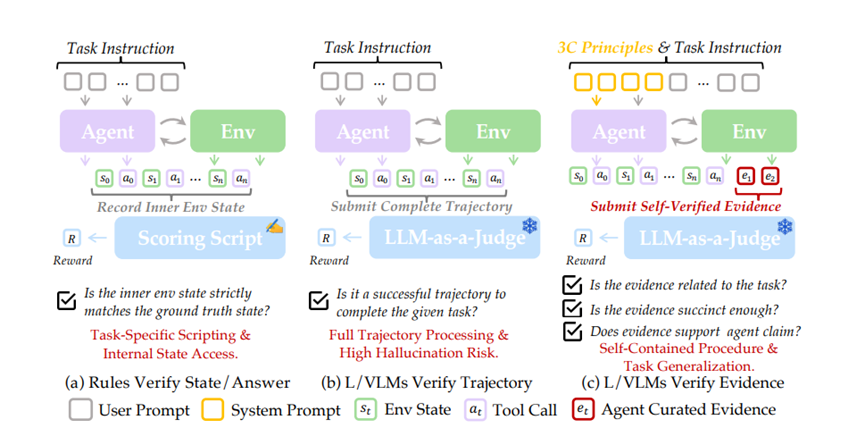
简洁性原则:证据不能太多太杂。没用的冗余信息要去掉,不然验证工具看得眼花缭乱,反而容易出错。一般来说,1到3个关键证据就够了,多了反而添乱。就像汇报工作,捡重点说就行,没必要堆砌所有细节。
创造性原则:如果现有的操作记录里没有足够的证据,智能体可以主动做一些额外动作来创造证据。比如任务完成后,主动截图关键页面,或者查看相关设置,确保有实打实的证据支撑。
为了让智能体更快掌握这套技巧,SmartSnap还设计了一套奖励机制:证据好就给奖励,证据差或格式不对就扣分。
比如,只要提交的证据和任务相关,不管任务最终成没成功,都能拿点小奖励,鼓励它关注任务本身;如果证据能明确证明任务成功,奖励更高;但如果证据太多太杂,或者格式不符合要求,就会被惩罚。
这套机制让智能体在训练中快速摸索出什么证据最有效、什么格式最规范,不用人手把手教。
可能有人觉得背后技术特别复杂,其实核心逻辑很朴素,没那么多玄乎的东西。
SmartSnap把整个过程看成一个增强版的决策流程。智能体的动作分成两类:一类是完成任务的操作,比如点击、输入文字;
另一类是提交证据的操作,比如上传截图或XML数据。每一步交互都会被记录下来,最后从中挑出最关键的证据提交。
这些证据也不是随便来的,而是智能体操作和环境反馈的成对记录。比如它点击了某个按钮,紧接着屏幕发生了什么变化,这一对信息就是一个核心证据。这种证据是客观事实,没法造假,比智能体自己说“我完成了”靠谱得多。
在模型选择上,研究团队用了LLaMA3.1和Qwen系列的几个常见模型,验证器则选了推理能力强的DeepSeek-R1。
训练时,监督微调阶段batchsize设为32,训练5轮;强化学习阶段batchsize为8,训练两轮共180步。所有实验都在64块GPU上跑,保证效率。
实验平台选了AndroidLab,用了其中726个训练任务和138个验证任务,而且完全没用平台自带的验证系统,全靠自己的方案验证,这样更能体现真实效果。
登录/注册后继续阅读
立即登录/注册 >































