
我要认证
2026-01-05
咱们都知道,现在的机器人要想干活,通常得有人手把手教,或者是写死代码,稍微换个环境就傻眼了。
但是斯坦福团队开发了一个脑洞特别大的框架Dream2Flow。他们想,既然现在的AI生成视频那么厉害,能不能让它先在脑子里把怎么干活给演一遍,然后机器人照着演就行了。
最关键的是,不用咱们人类的动作去教,而是用一种叫3D物体流的东西做中介,把视频生成和机器人控制连了起来,直接打破了两者之间的壁垒,说它是机器人操控领域的革命一点都不夸张。

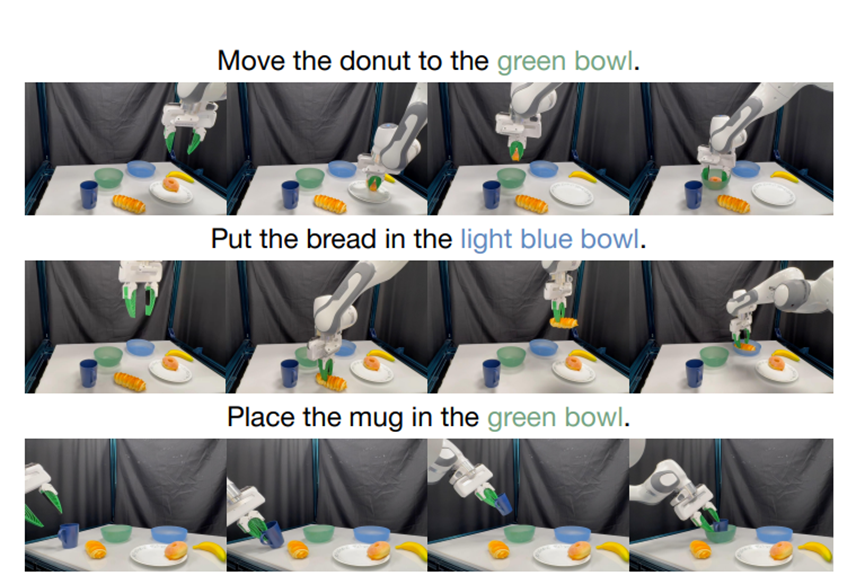
下面这个是斯坦福放出来的演示视频
咱们生活的世界太复杂了,机器人要面对的场景千变万化。从简单的把面包放进碗里,到稍微复杂点的拉椅子、开抽屉,都得让机器人明白要做啥、怎么动才对。以前的机器人想干活,得先给它看一大堆同类任务的演示视频,相当于手把手教。
可这么一来问题就来了,换个没教过的任务或者场景,机器人就瞬间变笨,完全不知道该咋整。
好在近几年生成式AI视频技术越来越强,给机器人干活提供了新思路。你只要给它一张初始图片和一句指令。
比如把面包放进碗里,它就能生成一段特别真实的操作视频,还能符合物理规律。这就像给机器人提前模拟了一遍操作过程,让它知道大概该怎么动。
但新的问题又冒出来了,视频里是人的动作,机器人的身体结构和人完全不一样啊。人能用手轻松抓握的动作,机器人的机械臂根本做不出来,这就是所谓的具身差距。
怎么把人类动作的核心信息提出来,变成机器人能看懂的指令,成了最大的难题。而Dream2Flow就是用3D物体流解决了这个问题,相当于在人和机器人之间架了一座翻译桥梁。
Dream2Flow的逻辑其实特别清晰,就靠三个核心模块配合,一步步把指令变成机器人的动作。
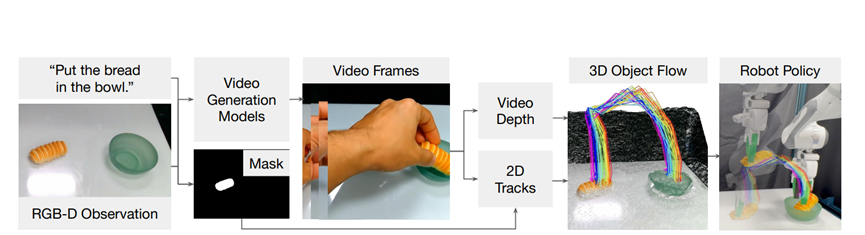
第一步视频生成让AI先脑补操作过程:这个模块就像机器人的大脑预演环节,输入很简单,一张机器人工作环境的照片和一句任务指令。它会调用现成的视频生成模型,直接生成一段展示任务完成过程的视频。
比如要让机器人开烤箱,指令就是打开烤箱,生成的视频里就会有一只手慢慢打开烤箱门的画面。而且为了后续步骤顺利,视频里的相机是固定不动的,这样能避免后续计算出错。
如果是一些需要精准定位的任务,比如把T形块推到平台中心,还会额外给视频模型看一张目标位置的照片,让它生成的视频更精准。
第二步3D物体流提取把视频变成机器人能懂的轨迹:这一步是整个框架的核心,相当于把刚才生成的2D视频,翻译成机器人能理解的3D运动路线。
咱们看视频只能看到平面动作,机器人干活得知道物体在三维空间里怎么动,所以这一步至关重要。
首先得给视频加深度信息,就像给平面画加上立体感,让机器人知道物体离自己有多远。然后用专门的模型把任务相关的物体圈出来,比如开烤箱任务里的烤箱门,排除背景干扰。
接着从物体上选一些关键点,在整个视频里跟踪这些点的运动,最后把这些2D平面上的运动轨迹,转换成3D空间里的坐标变化,这就是3D物体流。
简单说,这一步就是把“手怎么开门”的视频,变成了“烤箱门从哪个位置转到哪个位置”的精准数据,机器人一看就知道物体该怎么移动。

第三步动作推理把轨迹变成实际动作:这一步就是机器人的执行环节了,把刚才得到的3D物体流,变成机械臂能完成的具体动作。不同场景下,机器人的动作逻辑也不一样,咱们分情况说。
如果是模拟环境里推方块这种任务,机器人会先学一个动力学模型,知道推方块的哪个位置、用多大劲,方块会怎么动。然后随机试几种推的方式,选效果最好的那种执行。
登录/注册后继续阅读
立即登录/注册 >































